Storm实现实时feed信息处理
这篇文章通过用一个如何处理feed数据的应用场景来说明为什么会出现Storm实时计算框架, 对我们自己的技术选型和系统架构设计非常有参考价值.
原文在这里
Storm 成为最近开源社区的一个热门, 其作者Nathan Marz 所在的公司Backtype现在已经被Twitter收购. 该项目的wiki 非常完善. 从这里对Storm做一个全面了解.
目前的场景是这样的, 通过解析xml feed来生成索引数据. 已经通过搭建hadoop来批量生成全量索引. 但是如果需要实时更新数据增量生成索引该如何处理呢?
1.最简单单机方案
用一台机器持续抓取feed数据, 但是这个会受到单机的处理和网络带宽限制, 系统不具备可伸缩性.
2.可伸缩架构方案
通过多台机器搭建集群, 并根据feedId hash值取模将整个feed数据分散到多台机器. 这种方式缺点非常明显: 无法做到系统自动伸缩, 每加入一台机器, 需要重新调整整个集群的feed处理. 另外也无法实现自动容灾(failover), 一台机器挂了,必须手动启动备机.
3.Queue/Worker方案
通过在master上维护一个消息队列(queue), 然后分发到slave机器上的worker进行处理. 该方案能解决上一种方案中的其中一台机器挂掉造成的局部处理失败的问题.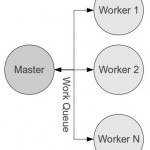
另外这种方案也是类似场景中的常用架构.
不过这种架构也有一些自己的复杂性: 比如消息队列的选择, 消息队列的运维问题.
4.Hadoop方案
采用Hadoop来更新feed, 这里需要编写Map/Reduce Job, 先将更新的feed导入Map中, 然后将所有数据汇总到Reduce, 这里每个Reduce处理其中一部分feed, 需要直到所有Reduce执行完成才能得到最终的索引结果. 因此实时性会大打折扣.
注:我觉得Hadoop更侧重于批量并行处理海量的数据, 而不是来一条更新数据处理一条.
5.Multi Queue/Worker方案
在原来的基础上再加一层Queue, 第一层N个worker从Work Queue获取feed数据, 然后添加到DB Queue, 最后M个(M<N)DB worker从DB Queue中获取数据更新到数据库或者其他地方. 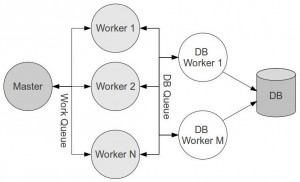
注:老实说我也没看出来为什么需要搞两层Queue. 但是Strom就是这么干的.
6.Storm方案
Storm对Multi Queue/Worker系统的复杂性进行了抽象. 用户只需要编写Topology而无需关系系统的扩展, 容灾以及进程间的通讯.
Storm集群包括一个master节点(Nimbus)和N个slave节点(Supervisor), 节点之间通过ZooKeeper来协调, 进程间通讯采用ZeroMQ. 而Topology不仅可以使用Java实现, 还支持其他动态语言.
这里我们使用FeedSpout来获取feed url并将其发射(emit)给FetcherBolt, 然后FetcherBolt去下载并解析数据.
下面是FeedSpout代码:
public class FeedSpout extends SimpleSpout { private static final long serialVersionUID = 1L; Queue<String> feedQueue = new LinkedList<String>(); String[] feeds; public FeedSpout(String[] feeds) { this.feeds = feeds; } @Override public void nextTuple() { String nextFeed = feedQueue.poll(); if(nextFeed != null) { collector.emit(new Values(nextFeed), nextFeed); } } @Override public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) { super.open(conf, context, collector); for(String feed: feeds) { feedQueue.add(feed); } } @Override public void ack(Object feedId) { feedQueue.add((String)feedId); } @Override public void fail(Object feedId) { feedQueue.add((String)feedId); } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("feed")); }}这里对例子进行了简化, 在FeedSpout构造器中直接传入feed数据, 然后在open方法中将其添加的内存queue中. 而Storm内部会负责控制nextTuple方法的调用. 这样来保证queue中的数据持续不断的被处理. 如果消息处理成功会调用ack方法, 失败会调用fail方法
下面是FetcherBolt方法:
public class FetcherBolt implements IRichBolt { private static final long serialVersionUID = 1L; private OutputCollector collector; @Override public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) { this.collector = collector; } @Override public void execute(Tuple input) { FeedFetcher feedFetcher = new HttpURLFeedFetcher(); String feedUrl = input.getStringByField("feed"); try { SyndFeed feed = feedFetcher.retrieveFeed(new URL(feedUrl)); for(Object obj : feed.getEntries()) { SyndEntry syndEntry = (SyndEntry) obj; Date entryDate = getDate(syndEntry, feed); collector.emit(new Values(syndEntry.getLink(), entryDate.getTime(), syndEntry.getDescription().getValue())); } collector.ack(input); } catch(Throwable t) { t.printStackTrace(); collector.fail(input); } } private Date getDate(SyndEntry syndEntry, SyndFeed feed) { return syndEntry.getUpdatedDate() == null ? (syndEntry.getPublishedDate() == null ? feed.getPublishedDate() : syndEntry.getPublishedDate()) : syndEntry.getUpdatedDate(); } @Override public void cleanup() { } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("link", "date", "description")); }}这里对Bolt也做了简化, 在execute方法中根据feed url下载并解析feed数据, 最后将数据发送出去(这里只发送了"link", "date", "description"字段), 这些数据将被下一个Bolt处理(如果有的话).
在Bolt中如果处理数据成功或失败, 将会调用ack或者fail方法. 在Storm内部会用Acker来跟踪Tuple的执行流程. Strom将发射Tuple(会带一个id)的操作称之为Anchoring, 如果一个Tuple在中间某个Bolt处理失败或者超时(内部默认是30s), Storm会向Spout发送FAIL消息, 这样我们就可以采用相应的策略来保证数据可靠.
最后是编写FeedTopology来封装Spout和Bolt:
package datasalt.storm.feeds;import backtype.storm.Config;import backtype.storm.StormSubmitter;import backtype.storm.generated.AlreadyAliveException;import backtype.storm.generated.InvalidTopologyException;import backtype.storm.generated.StormTopology;import backtype.storm.topology.TopologyBuilder;/*** This class builds the topology that needs to be submitted to Storm. It puts {@link FeedSpout}, {@link FetcherBolt}* and {@link ListingBolt} all together.** @author pere**/public class FeedTopology {public static StormTopology buildTopology(String[] feeds) {TopologyBuilder builder = new TopologyBuilder();// One single feed spout feeding databuilder.setSpout("feedSpout", new FeedSpout(feeds), 1);// Various (2) fetcher bolts -> shuffle grouping from feed spoutbuilder.setBolt("fetcherBolt", new FetcherBolt(), 2).shuffleGrouping("feedSpout");// One single listing bolt calculating statisticsbuilder.setBolt("listingBolt", new ListingBolt(), 1).globalGrouping("fetcherBolt");return builder.createTopology();}public static void main(String[] args) throws AlreadyAliveException, InvalidTopologyException {Config conf = new Config();conf.setDebug(true);conf.setNumWorkers(2);conf.setMaxSpoutPending(1);StormSubmitter.submitTopology("feedTopology", conf, buildTopology(Constants.FEEDS));}}更详细的例子可以从这里下载源代码
总结
通过上面的例子来说明Strom是什么, 以及如何使用Storm. 这里我们可以知道, 如果没有Storm, 要实现多层Queue/Worker架构将会是多么复杂. 而有了Storm, 我们只需要在Toplogy中实现我们的业务逻辑然后部署到Storm集群中即可. 而要对系统进行水平扩展, 只需要向Storm集群中添加机器即可.
另外Storm主要专注于实时计算, 而Hadoop则侧重于批量计算.
更多的例子常见这里 1 楼 qiuboboy 2012-02-08 引用
collector.emit(new Values(syndEntry.getLink(), entryDate.getTime(), syndEntry.getDescription().getValue()));
是不是应该改为
collector.emit(input,new Values(syndEntry.getLink(), entryDate.getTime(), syndEntry.getDescription().getValue()));