索引过程-index
可以说这个过程就是一个"shuffle"的过程,然后进行index操作。
?
流程:
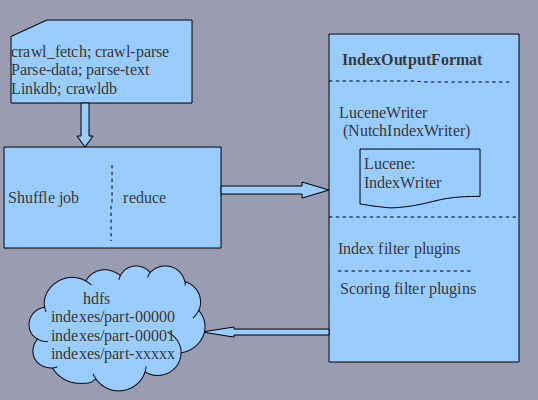
?
?
过程:
input: 这里有几个文件,来分析各文件的作用
crawl-fetch:当获取不到last-midified time时,用来fetch time代替
crawl-parse:no use
parse-data:conten-type;date等索引数据
parse-text:整个page全文检索
linkdb:取出指向当前url的所有的anchors进行索引
crawldb:获取之前score用以计算新的score
?
NOTE
*由于所有files的输入key都是Text(url),所以reduce可以将这些整合一起;
*其中fetch ,parse,crawldb格式是完全一样的;
*很多地方出现WRITABLE_REPR_URL_KEY,貌似这是旧版本的属性,see ReprUrlFixer.java
这些文件内容都可以从小结和fetch中找到
?
output
输出到indexes/part-xxxxx下
?
map
use default
?
reduce
这里主要是使用了IndexerOutputFormat来重写索引
由于数据来源是混合的,所以要处理时根据value类型进行了区分。其中进行了过滤:
if (fetchDatum == null || dbDatum == null || parseText == null || parseData == null) { return; // only have inlinks } //去掉不正常抓取的 if (!parseData.getStatus().isSuccess() || fetchDatum.getStatus() != CrawlDatum.STATUS_FETCH_SUCCESS) { return; }?奇怪的是,initMRJob()时明明outputValueClass是NutchWritale,但在reduce输出的却是NutchDocument?
经过测试,二者均可以。
?
plugins
index:BasicIndexFilter,AnchorIndexFilter,MoreIndexFitler.默认是前面二个
scoring:LinkAnalysisScoringFilter,OPICScoringFilter;默认是后面一个
?
在索引 时只处理了doc boost,所有的field weight是默认的;只有在查询时才处理。这样做就灵活可控了。
?
?
?
?
?
?
?
?
?
?
?
?
?