分析和优化云集群性能 使用可配置参数监视和调优 Hadoop 集群的性能
http://www.ibm.com/developerworks/cn/cloud/library/cl-cloudclusterperformance/index.html
?
简介
Hadoop 是一个灵活的开放源码 Java 框架,用于在一般硬件网络上执行大规模数据处理。它的思想来源于最初由 Google Labs 开发的 MapReduce 和 Global File System (GFS) 技术,由于具有高效、可靠和可伸缩的优点,它越来越流行了。Hadoop 现在是顶级 Apache 项目,IBM、Google、Yahoo! 和 Facebook 等许多公司都支持和使用 Hadoop,它已经成为大规模数据处理方面事实上的行业标准框架。
Hadoop 对于云计算意味着什么?云计算的目的之一是,以尽可能低的开销为计算机资源提供高可用性。Hadoop 能够处理数千个节点和 PB 量级的数据,可以自动地处理作业调度、部分失败和负载平衡,因此它是实现这个目标的完美工具。
要想充分使用计算机资源,优化性能是非常重要的,包括 CPU、内存和 I/O(磁盘和网络)。Hadoop 可以自动地改进性能,同时向用户提供接口,让他们可以针对自己的应用程序优化性能。本文介绍重要的 Hadoop 可配置参数以及分析和调优性能的方法。
回页首
建立环境
部署 Hadoop 环境的步骤
在执行性能调优之前,需要先构建 Hadoop 集群环境。步骤如下:
- 准备集群节点,在这些节点上安装 Linux OS、JDK 1.6 和 ssh。确保每个节点上都在运行 sshd。
- 访问
安装并配置 nmon 性能监视工具
nmon 是一个系统管理、调优和基准测试工具,可以简便地监视大量重要的性能信息。可以在整个性能调优过程中使用 nmon 作为监视工具。按以下步骤安装并配置 nmon,建立自己的性能监视系统:
- 从
在最后的 nmon 命令中,-f回页首Hadoop 可配置参数
Hadoop 提供许多配置选项,用户和管理员可以通过它们进行集群设置和调优。
core/hdfs/mapred-default.xml回页首如何调优和提高性能
介绍了上面的预备知识之后,现在讨论如何调优和提高性能。可以把整个过程划分为以下步骤。
步骤 1:选择测试基准
整个 Hadoop 集群的性能由两个方面决定:HDFS I/O 性能和 MapReduce 运行时性能。Hadoop 本身提供几个基准,比如用于 HDFS I/O 测试的步骤 2:构建基线
- 测试环境:
- 基准:Sort
- 输入数据规模:500 GB
- Hadoop 集群规模:10 个 DN/TT 节点
- 所有节点都是相同类型的
- 节点信息:
- Linux OS
- 两个 4 核处理器,支持并发多线程
- 32 GB 内存
- 5 个 500 GB 磁盘
- 测试脚本:下面是测试使用的脚本(关于运行 Sort 基准的更多信息参见
平均 CPU平均内存(活跃)平均磁盘平均网络 (KB/s)磁盘读 (KB/s)磁盘写 (KB/s)每秒 IO读写NameNode0.10%552.43MB0.018.11.78.031.8JobTracker0.30%822.19MB0.034.12.08.813.0DataNode42.5%6522.32MB49431.237704.0605.36134.97126.4
- 详细的图表:
获得所有 nmon 数据之后,可以使用 nmonanalyser 生成图表。因为 nmonanalyser 是一个 Excel 电子表格,所以只需打开它,单击步骤 3:寻找瓶颈
需要根据监视数据和图表仔细地研究系统瓶颈。因为主要的工作负载分配给 DN/TT 节点,所以应该首先观察 DN/TT 节点的资源使用量(下面只给出 DN/TT 节点的 nmon 图表以节省篇幅)。
通过研究基线监视数据和图表,可以发现系统中有几个瓶颈:在 map 阶段,没有充分使用 CPU(大多数时候不到 40%),而且磁盘 I/O 相当频繁。
步骤 4:打破瓶颈
首先尝试提高 map 阶段的 CPU 利用率。前面对 Hadoop 参数的说明指出,要想提高 CPU 利用率,需要增加
mapred.tasktracker.map平均 CPU平均内存(活跃)平均磁盘平均网络 (KB/s)磁盘读 (KB/s)磁盘写 (KB/s)每秒 IO读写NameNode0.10%520.88MB0.021.22.06.412.7JobTracker0.50%1287.4MB0.022.51.66.45.1DataNode48.4%12466.8MB51729.0744060.67669.974626865
图 5. 调优后的 DataNode/TaskTracker 图表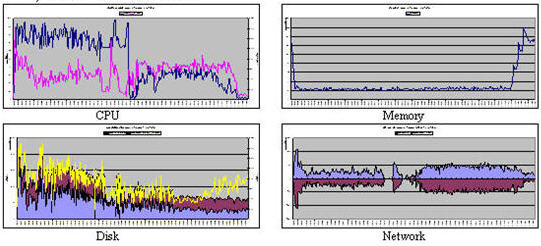 步骤 5:新一轮调优,重复步骤 3 和 4
步骤 5:新一轮调优,重复步骤 3 和 4增加每个 TaskTracker 中 map/reduce 任务的最大数量之后,观察获取的数据和图表,可以看到在 map 阶段已经充分使用 CPU 了。但是与此同时,磁盘 I/O 频率仍然很高,所以需要新一轮调优-监视-分析过程。
需要重复这些步骤,直到系统中没有瓶颈,每种资源都充分使用为止。
注意,每次调优不一定会提高性能。如果出现性能下降,需要恢复以前的配置,尝试用其他调优措施打破瓶颈。在这次测试中,最终取得的优化结果如下:
- 执行时间:5670 秒
- 系统参数值:机架间带宽 = 1Gb
- 资源使用量汇总:
图 6. DataNode/TaskTracker 图表 - 第二轮调优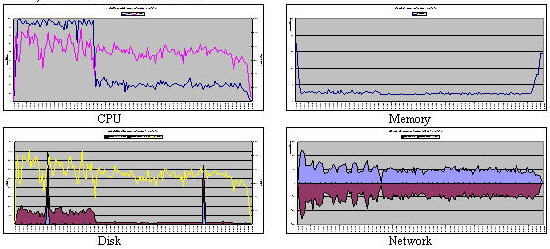 步骤 6:可伸缩性测试和改进
步骤 6:可伸缩性测试和改进为了进一步检验调优结果,需要在使用优化后的配置的情况下增加集群规模和输入数据规模,从而测试配置的可伸缩性。具体地说,把集群规模增加到 30 个节点,把输入数据规模增加到 1.5TB,然后再次执行上面的测试过程。
由于篇幅有限,这里不详细描述调优过程。监视和分析方法与上面提到的完全相同,发现的主要瓶颈出现在网络中。当输入数据增加到 TB 量级时,机架间带宽变得不足。把机架间带宽增加到 4 Gb,10 节点集群优化后的所有其他参数保持不变,最终的执行时间是 5916 秒,这相当接近 10 节点集群优化后的结果(5670 秒)。
回页首
结束语
您现在了解了如何监视 Hadoop 集群、使用监视数据分析系统瓶颈和优化性能。希望这些知识能够帮助您充分使用 Hadoop 集群,更高效地完成作业。可以使用本文描述的方法进一步研究 Hadoop 的可配置参数,寻找参数配置与不同作业特征之间的关联。
另外,这种基于参数的调优比较 “静态”,因为一套参数配置只对于一类作业是最优的。为了获得更大的灵活性,您应该研究 Hadoop 的调度算法,寻找提高 Hadoop 性能的新方法。
参考资料
学习
- 了解关于作者
Yu Li 是一位中国软件工程师。他是 IBM InfoSphere BigInsight 团队的成员,这个团队的任务是在 Apache Hadoop 上构建分析平台。他的专业领域包括云计算、性能调优、数据挖掘、数据库技术和中间件技术。
- 了解关于作者
- 测试环境:
- 从
 步骤 5:新一轮调优,重复步骤 3 和 4
步骤 5:新一轮调优,重复步骤 3 和 4 步骤 6:可伸缩性测试和改进
步骤 6:可伸缩性测试和改进