nutch1.4 部署应用
?
nutch1.4在2011年的11月26日正式发布了,nutch1.4之后更新了一些内容和一些配置,但是和1.3差别还是不大,但是和1.2之前的差异就比较大了,在nutch1.3之后,索引就用solr来进行生成了,包括查询也是用solr,所以在nutch1.2之前的web搜索服务也就不需要了。
首先我们去nutch的官网下载最新版的nutch1.4
地址为:
http://www.apache.org/dyn/closer.cgi/nutch/
?
下载apache-nutch-1.4-bin.zip或者apache-nutch-1.4-bin.tar.gz都可以
下载下来后,我们解压,现在先进行linux下的应用,下一节我会写eclipse中进行nutch开发
解压之后,我们会看到如下目录:
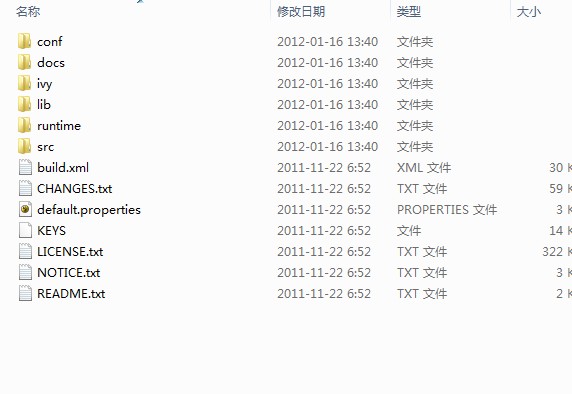
然后我们进入nutch/runtime/local的目录下,下目录下会有个conf文件夹,我们进入文件夹会看到如下文件:
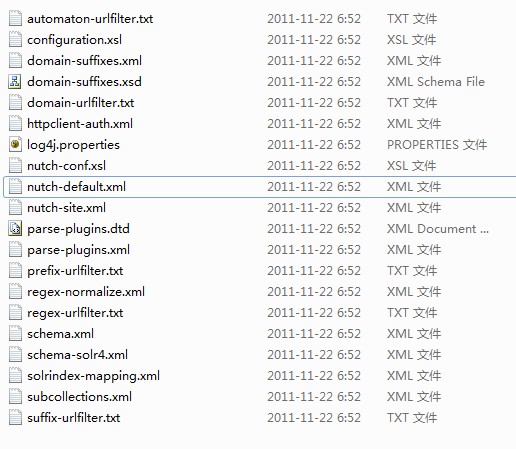
?在这里我们只需要知道2个文件即可:
nutch-default.xml和regex-urlfilter.txt
?
nutch-default.xml 是nutch 的配置文件
regex-urlfilter.txt文件内是编辑NUTCH爬取的策略规则的
?
我们这是进行初次爬取,那么我们测试的话不需要对其他设置进行优化,只需要做到如下即可:
在nutch-default.xml文件中找到http.agent.name属性,将其中的value内容加上;
?
?增加上属性后,我们还需要进行规则的设置,比如我们要爬取www.163.com ,但是我们不是要把里面的所有链接都爬取下来,如sohu的广告,我们就不需要爬,我们只需要爬取163的内容,那么我们就需要设置爬取规则,爬取规则采用正则表达式进行编写(正则表达式在这里不做具体阐述)
?
那么我们在哪里编写规则呢?
?
regex-urlfilter.txt文件中编写规则:
?
如果要以后查看日志的话,那么就在最后加上一个 >& (输出位置)
?
solr需要单独配置,我会在solr一篇文章中讲怎么部署,这里的-solr的位置,只需要输入solr的url地址即可
如想了解solr部署请看solr 部署的文章
?
如果要想在windows下测试或者开发,那么需要首先安装cygwin,安装cygwin我会在eclipse中部署nutch1.4中介绍
?
测试结果:
?
,好的,这几天一直在忙乎工作,周一加了通宵,没时间更新,实在不好意思啊…… at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:1252)
at org.apache.nutch.crawl.Injector.inject(Injector.java:217)
at org.apache.nutch.crawl.Crawl.run(Crawl.java:127)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:65)
at org.apache.nutch.crawl.Crawl.main(Crawl.java:55)
这个怎么解决了,看到了请速度给个反馈,谢谢!
at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:1252)
at org.apache.nutch.crawl.Injector.inject(Injector.java:217)
at org.apache.nutch.crawl.Crawl.run(Crawl.java:127)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:65)
at org.apache.nutch.crawl.Crawl.main(Crawl.java:55)
这个怎么解决了,看到了请速度给个反馈,谢谢!
请检查nutch-default.xml的plugin.folders是否修改为./src/plugin,默认为plugins,
修改后启动正常
一般是插件的地址问题!