memcache redundancy 机制分析及思考
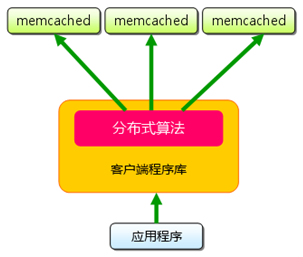
设计和开发可以掌控客户端的分布式服务端程序是件幸事,可以把很多事情交给客户端来做,而且可以做的很优雅。角色决定命运,在互联网架构中,web server必须冲锋在前,注定要在多浏览器版本以及协议兼容性方面呕心沥血。但要是做了web server的backend,就会好很多,可以让服务端程序独善其身,分布式的功能特性都由客户端来支持和实现。memcache就是这样的设计模式。memcache是后台架构必备的利器,关于其原理及源码分析可以直接google之,在此不再多说。最近项目中要考虑冗余和容错的问题,就把memcache redundancy机制分析了一下,仅供大家参考。
why
consistent hash能保证在向现有机器组里加入或移除一台机器时,不会造成hash映射关系大范围的改变。但一台cache机器down了,内容就没有了,缓存需要重建,数据库的压力就会上升,要是cache机器down的太多,就会有cache雪崩,故障在所难免。要是一个key=value可以存储在多台机器上,一台down了还有其它的顶着,岂不甚好,这就是redundancy机制。可惜,memcached不支持这个特性。It's not! Surprise! Memcached is a caching layer for your application. It is not designed to have any data redundancy.
显然memcached自身不想做这个特性,又一次把任务抛给了客户端。有需求就有实现,pecl/memcache在3.0之后已经开始支持这种机制。If data integrity is of greater importance a real replicating memcached backend such as "repcached" is recommended.
可以通过配置memcache来开启这个特性:memcache.redundancy = # default 1
how
下面就以pecl/memcache 3.0.6的代码分析一下redundancy具体的实现。
- set
先来看一下set操作的相关代码:/* schedule the first request */
mmc = mmc_pool_find(pool, key, key_len TSRMLS_CC);
result = mmc_pool_schedule(pool, mmc, request TSRMLS_CC);
/* clone and schedule redundancy-1 additional requests */
for (i=0; i < redundancy-1 && i < pool->num_servers-1; i++) {
mmc_queue_push(&skip_servers, mmc);
mmc = mmc_pool_find_next(pool, key, key_len, &skip_servers, &last_index TSRMLS_CC);
if (mmc_server_valid(mmc TSRMLS_CC)) {
mmc_pool_schedule(pool, mmc, mmc_pool_clone_request(pool, request TSRMLS_CC) TSRMLS_CC);
}
}
可以看出在set了一个key=value之后,还会set redundancy-1个clone。具体key的变换在mmc_pool_find_next函数:/* find the next server not present in the skip-list */
do {
keytmp_len = sprintf(keytmp, "%s-%d", key, (*last_index)++);
mmc = pool->hash->find_server(pool->hash_state, keytmp, keytmp_len TSRMLS_CC);
} while (mmc_queue_contains(skip_servers, mmc) && *last_index < MEMCACHE_G(max_failover_attempts));
key变换的规则很简单,1变N(key-i) ,进行N次set。
- get
get的时候当然是要以相同的方式来查找。但只要找到一个valid server就停止查找并返回。mmc_t *mmc = pool->hash->find_server(pool->hash_state, key, key_len TSRMLS_CC);
/* check validity and try to failover otherwise */
if (!mmc_server_valid(mmc TSRMLS_CC) && MEMCACHE_G(allow_failover)) {
unsigned int last_index = 0;
do {
mmc = mmc_pool_find_next(pool, key, key_len, NULL, &last_index TSRMLS_CC);
} while (!mmc_server_valid(mmc TSRMLS_CC) && last_index < MEMCACHE_G(max_failover_attempts));
}
think
memcache是通过将一个key=value变换成N个key=value来实现redundancy,这样可以和3.0.0之前的接口很好的兼容,但redundancy的key需要变换并随机分散在机器上,每次都要hash查找,也很不好管理。自己想了一种redundancy的设计,就是引入group的概念,在加入机器的时候,配置所属的group id,一个key只hash到一个group id,所有的请求都发到group,group里面的每台机器存储hash(key)到该group的全部内容。这样set/get只需要一次hash操作,同时也可以在group内设计更灵活的实现方式。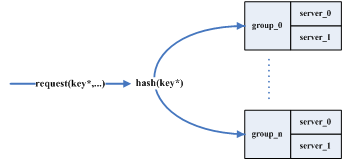
这只是个人的一点儿想法,欢迎大家拍砖指正。