JBPM工作流引擎内核设计思想及构架
3 什么是流程引擎内核?
我比较推崇“微内核的流程引擎构架”,并在最近两三年内写了两篇探讨此方面的文章:第一篇是写于05年7月份的《微内核流程引擎架构体系》,第二篇是07年7月份的《微内核过程引擎的设计思路和构架》(受普元《银弹》杂志约稿所写,尚未对外公开)。
但至今对外阐述引擎内核到底是什么。
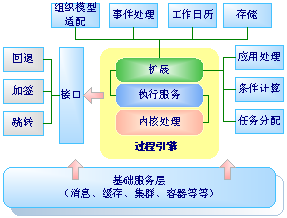
正如上面的两张图所示,我们可以通过“微内核”的构架来使得流程引擎的结构更加“清晰”。而能否实现“微内核”的根本,则是看你是否能够设计并抽象出“良好的引擎内核结构”。
很显然,要想设计出一套结构优良的引擎内核,首要条件就是:明白什么是引擎内核。
首先我们需要明白引擎是什么,引擎可以做什么。这在WfMC的《工作流参考模型》中已经有很详细的解答,本文不再重复。知道这个仅仅是不够的,你还需要很清晰的明白如何去“为流程建模”,而这则在Aalst大师所著的《工作流管理——模型、方法、系统》一书有细致阐述,本文也不再重复。
但很可惜,至今尚未有一本专门的书籍来论述“过程建模方法”的,或者说如何利用这些既有的“过程建模方法(诸如FSM、PetriNet、EPC、Activity Diagram等等)”来解决流程问题。这个只能分别查阅相关资料,此处也不叙述。因为文本只讲“引擎内核”。
如果我们暂且把那复杂的流程业务性问题,诸如“组织模型分配”、“分支条件计算”、“事件处理”、“消息调度”、“工作项处理”、“存储”、“应用处理”、以及那些“变态的诸如会签、回退之类的模型”都统统的抛弃,只留下“最单纯的过程性问题”,也就是“解决一个过程运行问题,按秩序的从一个节点到另一个节点的执行”。——这就是引擎内核所关注的根本问题。
上面这句话,估计会引起很多人“拍砖”。在很多人看来,工作流之所以看起来很“难”,就是因为这些复杂多变的“业务性问题”都统统绑在一个“引擎”上造成的。
其实,这是两个“维度”的问题,也就是“引擎的抽象”和“引擎的应用”这两个不同维度,不同层面的问题。但这绝不是两个独立的问题,“引擎的抽象”的好与坏,直接影响到“引擎的应用”的可复杂度和可支持度,当然我们也不能否认,“引擎的应用”问题也是一个很复杂的问题。但本文是站在“引擎的抽象”这个维度来阐述问题的。对于“引擎的应用”问题,可参考我的前作:2003年11月份的《工作流模型分析》、2003年12月份的《工作流授权控制模型》、2004年7月份的《工作流系统中组织模型应用解决方案》。
也就是说,本文不是指导大家如何去“使用jbpm”,而是阐述“jbpm的引擎的内核部分是如何构建的”。但本文的主旨不是告诉大家“jBpm是如何设计引擎内核的”,而是以jBpm为例,来介绍“引擎内核”。
对于一个节点来说,从定义角度,其只关心几个事情:
(1) 这是个什么类型的节点。这个节点可能是start state,也可能是一个task node,或者是一个fork。
(2) 这个节点的转入Transition和转出Transition。
可能有的人会说,还需要关心节点的转入转出的类型,比如And Splite或者Xor Join之类。这个并没有错,因为很多流程模型的节点元素需要考虑这个,比如WfMC的XPDL模型。但是jBpm的节点是没有这样的属性的,或者说的更准确些,是Activity Diagram模型的节点没有这样的特性。活动图是采用“Fork”、“Join”这样的节点来解决“分支”问题。
这是一张非常标准的“活动图”,如果我们用jbpm的设计器,看看这样一张“流程图”:
不论你如何绘画,改变不了这张图的本质:它就只有两个基本元素:节点和转移。只是有的节点是start-state,有的是task-node,有的是join,有的是end state而已。
当jbpm试图去启动一个流程的时候,首先是构造一个流程实例,并为此流程实例创建一个Root Token,并把这个Root Token放置在Start Node上。
以下截取部分代码实现,仅供参考。手头有jbpm3相应开发环境的朋友,可以打开ProcessInstance和Token这两个类。(注:以下所有参考代码,为了突出主题,都已经将实际代码中的event,log等处理删除)
Token的Signal操作表示:实例需要离开当前token所在的节点,转移到下一个节点上。因为Node与Node之间是“Transition”这个桥梁,所以,在转移过程中,会首先把Token放入相关连的Transtion对象中,再由Transition对象把Token交给下一个节点。
8 jBpm的过程执行机制
8.1 执行机制
前面我们的“过程调度机制”是为了让流程可以正确的从“一个节点转移到下一个节点”,而本节所要讲解的jbpm“执行机制”,则是为提供一个运行机制,来保证“节点的正确执行”。
首先我们需要明确如下的概念:
(1) 节点有很多中,每种节点的执行方式肯定是不一样的
(2) 节点有自己的生命周期,不同的生命周期阶段,所处的状态不同。
在WfMC的《工作流参考模型》文档中,为活动实例归纳了几个可参考的生命周期。(仅供参考,实际很多工作流引擎的节点的生命周期要比这复杂)
但是,jbpm并没有突出“节点生命周期”这个理念,仅仅只是在“Event”中体现出出来。在我看来,可能的原因有两个:
(1) jBpm没有NodeInstance这个概念。利用Token和TaskInstance,jBpm足以持久化足够的信息,能够让流程实例迅速定位到当前运行的状态。
(2) jBpm的Event已经很丰富,并且这个Event是围绕“Token的转移”而设置的,并不是围绕Node的生命周期设置的。
(3) 通常我们需要在Active和Completed的生命周期内所要操作的分支与聚合,在jBpm模型中分别由Fork、Join之类的节点替代。所以jBpm过分关注Node生命周期的管理意义不是非常大。
作为个人,我并不行赏jBpm这样抛弃“节点生命周期管理”的实现方式,更行赏OBE(最早的基于XPDL模型的java工作流引擎之一)的生命周期约束和管理。但是,也不得不承认,jBpm规避了“繁琐的状态维护”,反而让处理变得“简易”,也更容易被大家所理解和接受,而这也正是OBE逐渐消失的一个原因:过于复杂和臃肿。
让我们在前面那张jBpm的“调度机制思维图”上,再稍稍补充一点(为了突出显示,与上图有所改动)。
这张图应该可以很好的诠释出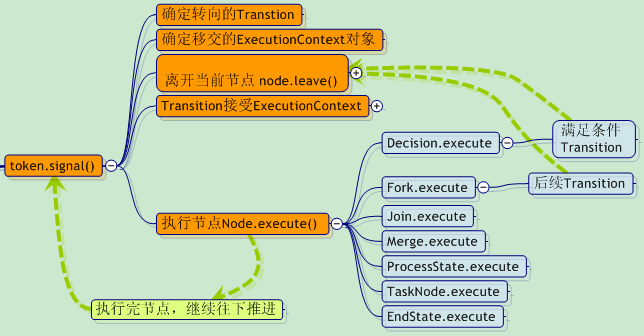 , jBpm是如何执行各种节点的,这也是得益于OO的“多态与继承”特性。
, jBpm是如何执行各种节点的,这也是得益于OO的“多态与继承”特性。
8.2 分支处理
jBpm的执行机制非常简单,但还是需要稍微补充一下有关“分支”方面的处理。
jBpm采用sub token的机制来解决分支方面的处理:当遇到有分支的时候,会为每个分支节点创建一个child token。在聚合节点(Join或Merge),则依赖其同步或异步的聚合方式,来分别处理。
比如我们参看Fork节点的执行代码(为了突出重点,省略部分代码):
10 后记
上半年写了些bpm和SOA的文章,也被csdn的好友拉着忽悠了不少这方面的概念,弄的好像我开始搞这方面的工作似的。其实不然,本质工作与这有“天壤之别”,完全是非常底层的java技术应用。而workflow,也有两三年没有从事这方面的开发了,所以写此篇文章,着实费了点功夫。
想痛痛快快写篇有关“引擎内核”的文章,这个想法由来以及了,却担心自己不足以诠释清楚,反而容易误导他人,遂中途多次放弃。
正如前面所说的那样,引擎内核的实现,并没有一套“固定的模式”或者“固定的实现体系”,会因为很多因素而造成实现不同。如果想把“引擎内核”的实现真正诠释清楚,必须把这些相关因素都诠释明朗——但这依然是一个浩大的工程。
前些日子,受朋友所托,为他们的公司学员讲了几节工作流的课程,期间尝试jBpm来诠释了一下引擎的实现思路,发现效果不错。——受此引发,遂萌发了以jBpm为实例,来简单诠释“流程引擎内核”想法。
耗时一周的业余时间,虽然还很难诠释自己的全部想法,但“点出几个要点”,还是应该有了。