disable table失败的处理
相信每一个维护hbase集群的运维人员一定碰到过disable失败,陷入无穷的"Region has been PENDING_CLOSE for too long..."状态,此时没有什么好的办法处理。经常需要重启集群。
这个问题产生的原因非常讨厌,经过一段时间的分析和验证,得到了根本原因。要理解它,必须从disable的原理说起:
disable线程是一个DisableTableHandler类,我们看它的handleDisableTable()方法,在while循环中先获取table的regions列表,然后调用BulkDisabler的bulkAssign()方法,等待bulkAssign()返回为true时则结束 在bulkAssign()方法中启动线程池,然后等待线程池超时,超时时间由hbase.bulk.assignment.waiton.empty.rit控制 在每个线程中,先从regions collection中得到regions列表,然后通知rs来处理该region,并且把该region放入RIT列表中,表示该region正在进行处理 rs处理完region以后,将该region状态在zk上置为closing,此时master得到通知 master将这个region从RIT列表中删除,并从regions列表中删除。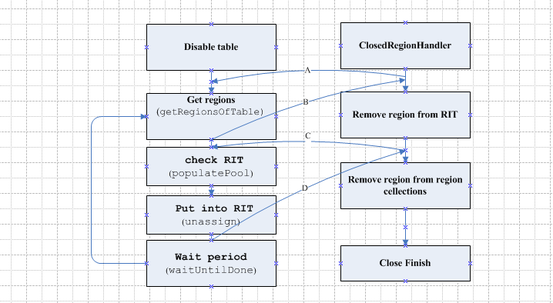
注意以上最后一步,当master把它从RIT中删除以后,还有短暂的时间这个region还在regions列表中,此时另一个线程拿到了这个region,并且此时这个region不处于RIT状态保护,于是另一个线程开始重复以上过程,而前一个线程己经把它从collection中删除了,于是后一个线程再也无法完成closing事件。直到RIT超时(默认30秒)。
于是有两个修改办法:
1 缩短hbase.bulk.assignment.waiton.empty.rit这个时间(默认10分钟,it's too long...),让它重新进行一轮disable,此时会先把RIT的region都处理掉再继续,这样多几次尝试总会成功的。
2 修改代码:(https://issues.apache.org/jira/secure/attachment/12487669/HBASE-4064_branch90V2.patch)
Index: src/main/java/org/apache/hadoop/hbase/master/AssignmentManager.java===================================================================--- src/main/java/org/apache/hadoop/hbase/master/AssignmentManager.java(revision 1150529)+++ src/main/java/org/apache/hadoop/hbase/master/AssignmentManager.java(working copy)@@ -767,14 +767,15 @@ * @param regionInfo */ public void regionOffline(final HRegionInfo regionInfo) {+ // remove the region plan as well just in case.+ clearRegionPlan(regionInfo);+ setOffline(regionInfo);+ synchronized(this.regionsInTransition) { if (this.regionsInTransition.remove(regionInfo.getEncodedName()) != null) { this.regionsInTransition.notifyAll(); } }- // remove the region plan as well just in case.- clearRegionPlan(regionInfo);- setOffline(regionInfo); }即在以上步骤5时,先从regions列表中删除,再清除它的RIT状态。
方法2己经测试成功,方法1更简单,各位被这个问题困扰的同学可以一试。 1 楼 杨俊华 2011-08-31 好文要顶!!
这个问题也困扰我,但我就是重启了事。惭愧惭愧!! 2 楼 lztaomin 2011-10-20 请问高手。hbase.bulk.assignment.waiton.empty.rit这个时间设置为多少合适? 3 楼 lc_koven 2011-10-20 lztaomin 写道请问高手。hbase.bulk.assignment.waiton.empty.rit这个时间设置为多少合适?
30秒吧...不过还是改代码靠谱 4 楼 wangjinpeng 2011-12-01 注意以上最后一步,当master把它从RIT中删除以后,还有短暂的时间这个region还在regions列表中,此时另一个线程拿到了这个region,并且此时这个region不处于RIT状态保护,于是另一个线程开始重复以上过程,而前一个线程己经把它从collection中删除了,于是后一个线程再也无法完成closing事件。直到RIT超时(默认30秒)。
以前遇到过这个问题,但是没有深究,今天看完你的处理,然后又去看了一下代码,发现有点地方不太清楚,这个是我看代码理解的重现过程:
前面都跟你分析的一致,从第二个线程进入开始:
1. 后一个线程拿到一个已经closed的region然后再去disable,不会阻塞,还是会发起closeRegion RPC给RS,然后RS发现online region里面没有这个,抛出NotServingRegionException,HMaster收到这个异常,记录log,然后线程正常退出,此时rit超时时间好像不会超时。
但是在发送RPC之前unassign方法里会执行这个代码
state = regionsInTransition.get(encodedName);
if (state == null) {
state = new RegionState(region, RegionState.State.PENDING_CLOSE);
regionsInTransition.put(encodedName, state);
}
但是RPC失败线程退出以后,没有将RegionState从RIT删掉,这个region的状态就变为:其实已经下线了,但是RegionState处在RIT中,且为pending——closing。
2. AssignmentManager有一个TimeoutMonitor是一个定时线程,专门用来检查RIT中的异常region,异常指在RIT中提留时间在3分钟以上的Region,并进行修复工作。默认10秒启动一次。启动以后检查到RIT中上面那个异常的Region(假如3分钟过去了),然后打印日志“Region has been PENDING_OPEN for too long, reassigning region=regionName”,然后尝试将它unassign,结果unassign的时候发现在assignment map中不存在这个region(已经被第一个线程setOffline删掉了),然后记录日志“Attempted to unassign region regionName but it is not currently assigned anywhere”,退出。下次10秒启动的时候又会发生,记录日志,在退出,不断循环。
问题应该虽然是disableTable引起的,不过log是TimeoutMonitor产生的,还有TimeoutMonitor的修复工作应该也还可以进一步优化优化。
看完代码的一点体会。。