Nutch 使用入门(一)——准备工作及Intranet抓取
/** *本人亦初学者,如有不正确的地方请多多指教。谢谢! **/
?
环境要求:
1.JDK1.5 或者更高。
2.Tomcat5.x 或者更高。
3.windows下需要Linux仿真环境Cygwin来提供Shell支持。
?
准备工作:
1.下载安装Nutch,你可以从
3.你需要给你的网络蜘蛛取一个名字,这是必须的。在Nutch目录下找到conf/nutch-default.xml文件,搜索http.agent.name,设置这个属性的值。这个属性值在抓取网页的时候,会携带于HTTP请求的协议头里面,用来表明网络蜘蛛的身份。
?
现在已经准备就绪,可用进行网页的抓取了。
我们有两种方式可以使用。
1.使用一步到位的crawl命令,这通常用于intranet的抓取。操作很简便,但是有许多限制。
2.更加灵活方便的互联网抓取模式。使用一些更加底层的命令,如inject,generate,fetch,updatedb。
?
首先,我们一步一步来实现第一种方式。
1.在Nutch安装目录下新建一个urls目录,在urls目录中添加一个文本文件,其内容可以是你想抓取的网站的url地址。我的示例地址为www.sina.com.cn.
2.修改conf/crawl-urlfilter.txt.过滤规则以“+”表示允许下载。默认的规则如下:
?+^http://([a-z0-9]*\.)*MY.DOMAIN.NAME/
如果只允许下载iteye.com的网页,可以更改设置为+^http://([a-z0-9]*\.)*sina.com.cn/
3.执行crawl命令。典型的命令如下:
bin/nutch crawl urls -dir javaeye -depth 3 -topN 100 -threads 3
?-dir :存放爬行结果的目录
?-depth:抓取的页面深度
?-topN:每一层抓取前N个URL
?=threads:下载的线程数目
?
等这一步完成以后,就可以进行搜索了。
4.搜索。
将Nutch目录下面Nutch-1.0.war部署到tomcat的wepapp目录下,启动tomcat.在解压后的nutch-1.0目录下找到nutch-site.xml文件,修改其内容如下:
<configuration><property><name>http.agent.name</name><value>yourAgentName</value></property><property><name>searcher.dir</name><value>D:/nutch-1.0/javaeye</value></property></configuration>
? 重新启动Tomcat。通过浏览器访问:http://localhost:8080/nutch-1.0 ,将看到如下搜索页面:
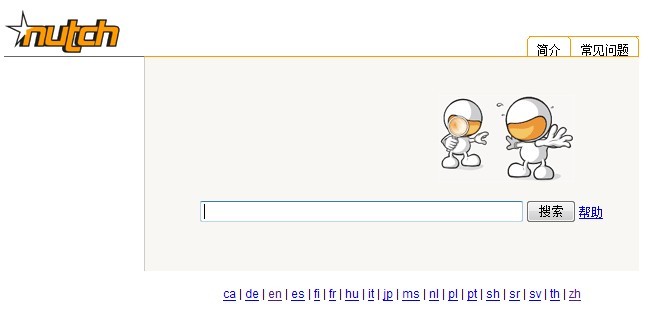
? 输入你希望搜索的关键字,开始进行搜索体验吧!
?
?
?还有一些问题需要解决:
?
?1. 搜索中文出现乱码,但这并不是nutch的问题,修改tomcat配置文件tomcat6\conf\server.xml。增加URIEncoding/useBodyEncodingForURI两项。
<Connector port="8080" protocol="HTTP/1.1"connectionTimeout="20000"redirectPort="8443"URIEncoding="UTF-8"useBodyEncodingForURI="true"/>
?2.网页快照出现乱码,修改webapps\
?