获取世界大学数据(人人网)
今天闲来无事,凭着对大数据和海量数据的浓厚兴趣,把很久之前想写但没写完的程序坚持写完了,下面简要介绍一下吧。
这些程序的主要目的是统计世界大学的信息,主要的数据来源就是人人网了,在人人网上有一个接口,就是在查询大学数据的时候,通过Ajax会向后台发送一个请求(http://s.xnimg.cn/a27085/allunivlist.js),这个请求的返回值就是一个js文件,而这个js文件就是一个很大的json对象,然后通过解析这个json对象就可以得到世界大学的信息了。
原来在论坛里面已经有人对此做了实现(http://www.iteye.com/topic/1118508),不过貌似比较复杂,源码看得都累了,所以自己想做一个实现,简化一些操作。
首先就是要保存下来这个js文件,对保存下来的js文件稍作修改:var allUnivList = [{"id":"00","univs":"",改成[{"id":0,"univs":"",也就是把前面变量定义去掉,因为已经没用了,还有就是把00改成0。基本上就是这些,下面是工程的源代码:
首先说明一下,要看得懂这里的源代码,其实还是需要花费一段时间的,主要就是对那个很大的json对象要很熟悉,下面是我整理出的一个对象框架,希望能让读者受益:(考虑到阅读方便,这里已经做了转码)
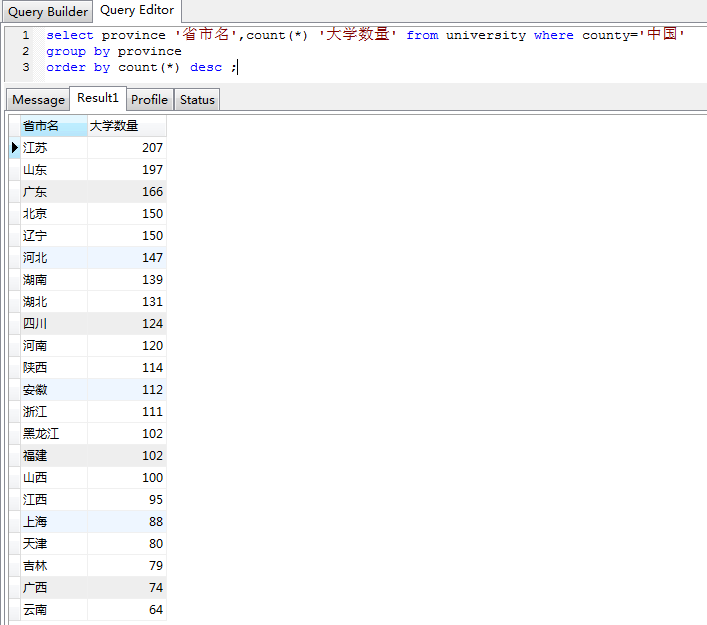
首先比较惊讶的应该是中国和美国的差距,然后就是小日本这样的弹丸之国居然有这么高的大学数量,确实很让人深思。
然后还有一张就是下面的这张图片,这样看的话,江苏很给力呀,如果不出意外的话这张图基本上就代表了省市的经济实力吧,呵呵。
好吧,还是以技术为主,其他的还是少聊吧,项目中用到了json-lib,打包的项目放在附件中,有兴趣的可以去下载。
?
1 楼 rensanning 2012-05-04 JS文件也就1M,谈不上大数据量。
可以使用Jackson来解析JSON,很容易实现Bean的嵌套。参考http://rensanning.iteye.com/blog/1474603中的源码TiJson.rar! 2 楼 yiyiboy2010 2012-05-04 rensanning 写道JS文件也就1M,谈不上大数据量。
可以使用Jackson来解析JSON,很容易实现Bean的嵌套。参考http://rensanning.iteye.com/blog/1474603中的源码TiJson.rar!
你说的那个东西我没用过,不过在这个程序中,Bean嵌套效率应该不是很高,当一个国家的数据解析完之后,那个对象会变的很大,然后插入到数据库中就会出现问题,之前就是在这个问题上纠结了很久,最后才采用了折中的方式来缓解大对象的问题。呵呵,感谢你提出的建议,关于那个东西我再去研究下。
关于数据量的问题,应该是相对来讲的吧,怎么着也有一万多行数据,对于个人计算机要插入所有的数据到数据库中还是需要一段时间的。不过相对企业级的应用,确实是太少了,做这个东西的一个动力就是以后可以在自己做的项目中使用到现在整理的数据,因为我还没有找到一个比较好的方式来获取这一类的信息。