Hibernate 与 原生 Jdbc 批量插入时的差距
源于很久以前写过的一篇贴子.
目的只为了看看 Hibernate 与 原生 Jdbc 批量插入时的差距到底在多少以内.
还是分别以 1W, 10W, 50W, 100W 做为测试. 如果数据量再大一点, 自己都建议自己直接使用文件导入的方式吧!
机器配置:
CPU : Genuine Intel(R) CPU T2080 @ 1.73GHzMemory : 1G
mysql version:
mysql> select version();+------------------+| version() |+------------------+| 5.1.32-community |+------------------+1 row in set (0.00 sec)
domain 简单到一种令人发指的地步:
package com.model;import java.io.Serializable;import java.sql.Timestamp;import java.util.UUID;import javax.persistence.Column;import javax.persistence.Entity;import javax.persistence.Id;import javax.persistence.Table;/** * @author <a href="liu.anxin13@gmail.com">Tony</a> */@Entity@Table(name = "T_USERINFO")@org.hibernate.annotations.Entity(selectBeforeUpdate = true, dynamicInsert = true, dynamicUpdate = true)public class UserInfo implements Serializable {private static final long serialVersionUID = -4855456169220894250L;@Id@Column(name = "ID", length = 32)private String id = UUID.randomUUID().toString().replaceAll("-", "");@Column(name = "CREATE_TIME", updatable = false)private Timestamp createTime = new Timestamp(System.currentTimeMillis());@Column(name = "UPDATE_TIME", insertable = false)private Timestamp updateTime = new Timestamp(System.currentTimeMillis());// setter/getter}spring:
<?xml version="1.0" encoding="UTF-8"?><beans xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns="http://www.springframework.org/schema/beans"xmlns:context="http://www.springframework.org/schema/context"xmlns:tx="http://www.springframework.org/schema/tx"xmlns:aop="http://www.springframework.org/schema/aop"xsi:schemaLocation="http://www.springframework.org/schema/beanshttp://www.springframework.org/schema/beans/spring-beans-2.5.xsdhttp://www.springframework.org/schema/contexthttp://www.springframework.org/schema/context/spring-context-2.5.xsdhttp://www.springframework.org/schema/txhttp://www.springframework.org/schema/tx/spring-tx-2.5.xsdhttp://www.springframework.org/schema/aophttp://www.springframework.org/schema/aop/spring-aop-2.5.xsd"><context:component-scan base-package="com.dao,com.service" /><context:property-placeholder location="classpath:jdbc.properties" /><bean id="dataSource" value="${jdbc.driver}" /><property name="jdbcUrl" value="${jdbc.url}" /><property name="user" value="${jdbc.username}" /><property name="password" value="${jdbc.password}" /><property name="maxPoolSize" value="50" /><property name="minPoolSize" value="5" /><property name="initialPoolSize" value="5" /><property name="acquireIncrement" value="5" /><property name="maxIdleTime" value="1800" /><property name="idleConnectionTestPeriod" value="1800" /><property name="maxStatements" value="1000" /><property name="breakAfterAcquireFailure" value="true" /><property name="testConnectionOnCheckin" value="true" /><property name="testConnectionOnCheckout" value="false" /></bean><bean id="sessionFactory"ref="dataSource" /><property name="configLocation" value="classpath:hibernate.cfg.xml" /></bean><bean id="hibernateTemplate" ref="sessionFactory" /></bean><bean id="jdbcTemplate" ref="dataSource" /></bean><bean id="transactionManager"ref="sessionFactory" /></bean><tx:advice id="txAdvice" transaction-manager="transactionManager"><tx:attributes><tx:method name="*" isolation="READ_COMMITTED"rollback-for="Throwable" /></tx:attributes></tx:advice><aop:config><aop:pointcut id="services" expression="execution(* com.service.*.*(..))" /><aop:advisor advice-ref="txAdvice" pointcut-ref="services" /></aop:config></beans>Hibernate:
<?xml version='1.0' encoding='UTF-8'?><!DOCTYPE hibernate-configuration PUBLIC "-//Hibernate/Hibernate Configuration DTD 3.0//EN" "http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd"><hibernate-configuration><session-factory><property name="hibernate.dialect">org.hibernate.dialect.MySQLDialect</property><!-- <property name="hibernate.jdbc.batch_size">50</property> --><!-- 下面两句注释与否, 测试时也会有很大差别 --><property name="hibernate.order_inserts">true</property><property name="hibernate.order_updates">true</property><!-- 表生成后请改为 none --><property name="hibernate.hbm2ddl.auto">update</property><!-- 如果数据量不多看看生成的 SQL 语句, 否则还是免了吧... --><property name="hibernate.show_sql">false</property><property name="hibernate.format_sql">false</property><property name="hibernate.current_session_context_class">org.hibernate.context.ThreadLocalSessionContext</property><mapping /></session-factory></hibernate-configuration>
数据交互(Hibernate):
package com.dao;import java.io.Serializable;import java.sql.SQLException;import org.apache.log4j.Logger;import org.hibernate.HibernateException;import org.hibernate.Query;import org.hibernate.Session;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.beans.factory.annotation.Qualifier;import org.springframework.orm.hibernate3.HibernateCallback;import org.springframework.orm.hibernate3.HibernateTemplate;import org.springframework.stereotype.Repository;/** * @author <a href="mailto:liu.anxin13@gmail.com">Tony</a> */@Repository("hibernateDAO")public class HibernateDAO<T extends Serializable> {private static final Logger log = Logger.getLogger(HibernateDAO.class);@Autowired@Qualifier("hibernateTemplate")private HibernateTemplate template;public Serializable save(T entity) {try {return template.save(entity);} catch (Exception e) {log.info("save exception : " + e.getMessage());throw new RuntimeException(e);}}public void flush() {try {template.flush();} catch (Exception e) {log.error("flush exception : " + e.getMessage());throw new RuntimeException(e);}}public int executeByHql(String hql, Object... values)throws HibernateException {try {return template.bulkUpdate(hql, values);} catch (Exception e) {log.error("executeByHql exception : " + e.getMessage());throw new HibernateException(e);}}public void clear() {try {template.clear();} catch (Exception e) {log.error("clear exception : " + e.getMessage());throw new RuntimeException(e);}}public void execute(final String sql, final Object... values) {template.execute(new HibernateCallback() {public Object doInHibernate(Session session) throws HibernateException,SQLException {Query query = session.createSQLQuery(sql);int i = 0;for (Object obj : values) {query.setParameter(i++, obj);}return query.executeUpdate();}});}}业务逻辑:
package com.service;import java.util.Date;import org.apache.log4j.Logger;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.beans.factory.annotation.Qualifier;import org.springframework.stereotype.Service;import com.dao.HibernateDAO;import com.model.UserInfo;import com.util.Global;import com.util.StringUtils;/** * @author <a href="mailto:liu.anxin13@gmail.com">Tony</a> */@Service("hibernateService")public class HibernateService {private static final Logger log = Logger.getLogger(HibernateService.class);@Autowired@Qualifier("hibernateDAO")private HibernateDAO<UserInfo> dao;public void testOcean(long num) {UserInfo user = null;log.info("start test Hibernate...");long begin = System.currentTimeMillis();for (int i = 1; i < (num + 1); i++) {user = new UserInfo();dao.save(user);user = null;if (Global.IS_BATCH) {if (i % Global.BATCH_NUMBER == 0) {dao.flush();dao.clear();}}if (i % 20000 == 0)System.out.printf("%s [%8d] number with a count...\n", StringUtils.getStringFromDate(new Date(), ""), i);}long end = System.currentTimeMillis();log.info("insert " + num + " count, consume " + (end - begin) / 1000.00000000 + " seconds");}public int count() {long begin = System.currentTimeMillis();int rt = dao.executeByHql("SELECT COUNT(ID) FROM UserInfo");long end = System.currentTimeMillis();log.info("query count, consume [" + (end - begin) / 1000.00000000 + "] seconds");return rt;}public void truncate() {long begin = System.currentTimeMillis();// 执行 native SQLdao.execute("TRUNCATE T_USERINFO");long end = System.currentTimeMillis();log.info("truncate table, consume [" + (end - begin) / 1000.00000000 + "] seconds");}}Test:
package com.test;import org.apache.log4j.Logger;import org.junit.Test;import org.junit.runner.RunWith;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.beans.factory.annotation.Qualifier;import org.springframework.test.context.ContextConfiguration;import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;import com.service.HibernateService;import com.util.Global;/** * @author <a href="mailto:liu.anxin13@gmail.com">Tony</a> */@RunWith(SpringJUnit4ClassRunner.class)@ContextConfiguration(locations = { "classpath:applicationContext.xml" })public class TestHibernate {private static final Logger log = Logger.getLogger(TestHibernate.class);@Autowired@Qualifier("hibernateService")private HibernateService hibernate;@Testpublic void testHibernate() {hibernate.testOcean(Global.NUM);System.err.printf("see momory! have a quick please...\n");try {Thread.sleep(10000);} catch (Exception e) {log.error("exception: " + e.getMessage());}}// @Testpublic void testCount() {log.info("count: " + hibernate.count());}// @Testpublic void truncate() {hibernate.truncate();}}下面主要来说说 Native Jdbc 的两种方式.
第 1 种自然是 addbatch. 这种方式可以使用 PreparedStatement, 能防止被 SQL 注入. 但从来 鱼与熊掌 是很难兼得的, 保证了数据安全的同时势必会也丢失一些性能.
第 2 种是以拼接字符串的形式, 将多条记录拼成一条 SQL, 进行执行, 这样一来, 执行一条语句就插入了多条记录, 但是容易被注入, 如果采用这种方式, 须用正则做一些"复杂"的处理. 这种方式是后来想到的, 只测了 100W 时的情况.
数据交互(native Jdbc):
package com.dao;import java.io.IOException;import java.sql.Connection;import java.sql.DriverManager;import java.util.Properties;import org.apache.log4j.Logger;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.beans.factory.annotation.Qualifier;import org.springframework.jdbc.core.JdbcTemplate;import org.springframework.stereotype.Repository;/** * @author <a href="mailto:liu.anxin13@gmail.com">Tony</a> */@Repository("jdbcDAO")public class JdbcDAO {private static final Logger log = Logger.getLogger(JdbcDAO.class);@Autowired@Qualifier("jdbcTemplate")private JdbcTemplate template;public Connection getConn() {try {return template.getDataSource().getConnection();} catch (Exception e) {log.info("获取连接时异常: " + e.getMessage());throw new RuntimeException(e);}}// 如果感觉使用 spring 获取的 Connection 太慢, 直接使用下面的直连...private static Properties p = new Properties();static {try {p.load(JdbcDAO.class.getClassLoader().getResourceAsStream("jdbc.properties"));} catch (IOException e) {}}public Connection getConnection() {try {String driver = p.getProperty("jdbc.driver");String url = p.getProperty("jdbc.url");String user = p.getProperty("jdbc.username");String password = p.getProperty("jdbc.password");Class.forName(driver);return DriverManager.getConnection(url, user, password);} catch (Exception e) {log.error("connection exception: " + e.getMessage());throw new RuntimeException(e);}}}业务逻辑:
package com.service;import java.sql.Connection;import java.sql.PreparedStatement;import java.sql.ResultSet;import java.sql.Statement;import java.util.Date;import org.apache.log4j.Logger;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.beans.factory.annotation.Qualifier;import org.springframework.stereotype.Service;import com.dao.JdbcDAO;import com.model.UserInfo;import com.util.Global;import com.util.StringUtils;/** * @author <a href="mailto:liu.anxin13@gmail.com">Tony</a> */@Service("jdbcService")public class JdbcService {private static final Logger log = Logger.getLogger(JdbcService.class);@Autowired@Qualifier("jdbcDAO")private JdbcDAO dao;/** * 使用 addbatch 的方式进行海量插入 * * @param num */public void testOcean(long num) {// 使用 spring 获取连接Connection conn = dao.getConn();try {conn.setAutoCommit(false);String sql = "INSERT INTO T_USERINFO(CREATE_TIME, ID) VALUES(?, ?)";PreparedStatement pstm = conn.prepareStatement(sql);UserInfo user = null;log.info("start test jdbc...");long begin = System.currentTimeMillis();for (int i = 1; i < (num + 1); i++) {// 要保证公平, 也在循环中 new 对象user = new UserInfo();pstm.setTimestamp(1, user.getCreateTime());pstm.setString(2, user.getId());pstm.addBatch();user = null;// 批处理if (Global.IS_BATCH) {if (i % Global.BATCH_NUMBER == 0) {pstm.executeBatch();conn.commit();pstm.clearBatch();}}if (i % 20000 == 0)System.out.printf("%s [%8d] number with a count...\n", StringUtils.getStringFromDate(new Date(), ""), i);}pstm.executeBatch();conn.commit();pstm.clearBatch();long end = System.currentTimeMillis();log.info("insert " + num + " count, consume " + (end - begin) / 1000.00000000 + " seconds");} catch (Exception e) {log.error("exception: " + e.getMessage());throw new RuntimeException(e);} finally {try {conn.close();} catch (Exception e) {conn = null;}}}/** * 使用拼接字符串的方式进行海量插入 * * @param num */public void testOceanWithSplit(long num) {Connection conn = dao.getConn();try {conn.setAutoCommit(false);Statement st = conn.createStatement();StringBuilder sql = new StringBuilder();String str = "INSERT INTO T_USERINFO(CREATE_TIME, ID) VALUES ";sql.append(str);UserInfo user = null;log.info("start test jdbc with split...");long begin = System.currentTimeMillis();for (int i = 1; i < (num + 1); i++) {// 要保证公平, 也在循环中 new 对象user = new UserInfo();sql.append("('").append(user.getCreateTime());sql.append("', '");sql.append(user.getId()).append("'),");user = null;// 批处理if (Global.IS_BATCH) {if (i % Global.BATCH_NUMBER == 0) {// 执行并提交至数据库st.execute(sql.deleteCharAt(sql.length() - 1).toString());conn.commit();// 重新开始拼接字符串sql.delete(str.length(), sql.length());}}if (i % 20000 == 0)System.out.printf("%s [%8d] number with a count...\n", StringUtils.getStringFromDate(new Date(), ""), i);}// 如果 总数据量不能整除批量数则将余下的数据进行执行if (num % Global.BATCH_NUMBER != 0) {st.execute(sql.deleteCharAt(sql.length() - 1).toString());conn.commit();}long end = System.currentTimeMillis();log.info("insert " + num + " count, consume " + (end - begin) / 1000.00000000 + " seconds");} catch (Exception e) {log.error("exception: " + e.getMessage());throw new RuntimeException(e);} finally {try {conn.close();} catch (Exception e) {conn = null;}}}/** * 查询数据量 * * @return */public int count() {int rt = 0;Connection conn = dao.getConn();long begin = System.currentTimeMillis();String sql = "SELECT COUNT(*) FROM T_USERINFO";try {ResultSet rs = conn.createStatement().executeQuery(sql);rs.next();rt = rs.getInt(1);} catch (Exception e) {log.error("exception: " + e.getMessage());throw new RuntimeException(e);} finally {try {conn.close();} catch (Exception e) {conn = null;}}long end = System.currentTimeMillis();log.info("query count, consume [" + (end - begin) / 1000.00000000 + "] seconds");return rt;}/** * 清表 */public void truncate() {// 使用直连获取连接.Connection conn = dao.getConnection();String sql = "TRUNCATE T_USERINFO";long begin = System.currentTimeMillis();try {conn.createStatement().executeUpdate(sql);} catch (Exception e) {log.error("exception : " + e.getMessage());throw new RuntimeException(e);} finally {try {conn.close();} catch (Exception e) {conn = null;}}long end = System.currentTimeMillis();log.info("truncate table, consume [" + (end - begin) / 1000.00000000 + "] seconds");}}Test:
package com.test;import org.apache.log4j.Logger;import org.junit.Test;import org.junit.runner.RunWith;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.beans.factory.annotation.Qualifier;import org.springframework.test.context.ContextConfiguration;import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;import com.service.JdbcService;import com.util.Global;/** * @author <a href="mailto:liu.anxin13@gmail.com">Tony</a> */@RunWith(SpringJUnit4ClassRunner.class)@ContextConfiguration(locations = { "classpath:applicationContext.xml" })public class TestJdbc {private static final Logger log = Logger.getLogger(TestJdbc.class);@Autowired@Qualifier("jdbcService")private JdbcService jdbc;@Testpublic void testJdbcWithSplit() {jdbc.testOceanWithSplit(Global.NUM);nothing();}// @Testpublic void testJdbc() {jdbc.testOcean(Global.NUM);nothing();}// @Testpublic void truncateJdbc() {jdbc.truncate();}public void nothing() {System.err.printf("see momory! have a quick please...\n");try {Thread.sleep(10000);} catch (Exception e) {log.error("exception: " + e.getMessage());}}// @Testpublic void testCount() {int count = jdbc.count();log.info("count: " + count);}}最终的结果, 个人总觉得并不客观, 之前的数据执行完, 测试下一种时, 我并没有将数据库中的数据清掉, 这样一来, 越到后期效率越低.
首先来说内存.

第一个是 eclipse 的使用率. 下面的 都差不多, 只是时间上挺让人郁闷的.
这里面有一个例外, 使用 Jdbc 测 50W 条数据的时候, 内存很高, 一度达到与 eclipse 匹敌的程度.
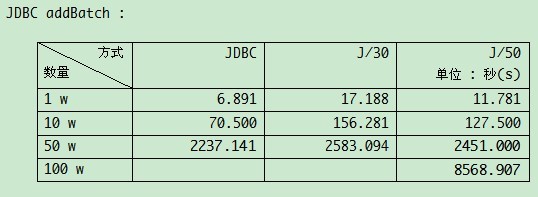
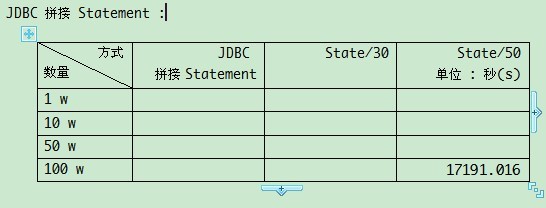
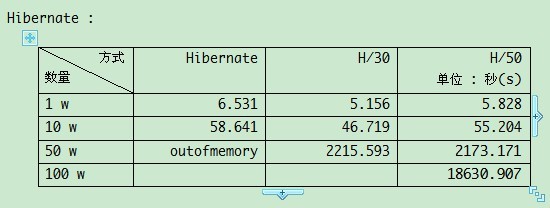
testOceanWithSplit - insert 1000000 count, consume 8568.907 seconds
JdbcService - insert 1000000 count, consume 17191.016 seconds
HibernateService - insert 1000000 count, consume 18630.907 seconds
count - query 3008200 count, consume [214.469] seconds
乖乖, 一条 select count 居然花了这么久

这结果挺搞的, 不是吗? 没曾想 add batch 的效率还不如 hibernate. 确信自己长这么大没有碰到过什么或灵异或诡异的事, 所以有没有哪位哥门机器配置比我要好的(估计没有比我差的). 帮忙看看. 效率到底差了多少
ps : lib 包中 缺了 spring.jar , 更改 jdbc.properties 连接方式, 更改 Global 接口中的相应常量再运行 TestHibernate 及 TestJdbc 即可. 每次执行完. 最好能把表给清了, 不然会显得不是很公平.
看来看去, 总觉得瓶颈是在数据库连接与 IO 读写的地方纠结着, 找不到去天堂的路!
点快了, 本想发到博客, 却发到论坛了. 主要是坛子里喷的人太多, 只添乱却很少提啥建设性的意见...public class test { public static Connection cn; static { try { Class.forName("oracle.jdbc.OracleDriver"); cn = DriverManager.getConnection//隐去 } catch (SQLException ex) { Logger.getLogger(test.class.getName()).log(Level.SEVERE, null, ex); } catch (ClassNotFoundException ex) { Logger.getLogger(test.class.getName()).log(Level.SEVERE, null, ex); } } public static void main(String[] args) throws SQLException { cn.setAutoCommit(false); test(100, 10); test(1000, 100); test(10000, 1000); test(100000, 1000); cn.close(); } static void test(int count, int commitlength) throws SQLException { System.out.println("测试:数据长度[" + count + "],每" + commitlength + "提交一次"); Long d1 = System.currentTimeMillis(); clear(); Long d2 = System.currentTimeMillis(); updateString(count, commitlength); Long d3 = System.currentTimeMillis(); clear(); Long d4 = System.currentTimeMillis(); updatePrepared(count, commitlength); Long d5 = System.currentTimeMillis(); clear(); Long d6 = System.currentTimeMillis(); updatePrepared(count, commitlength); Long d7 = System.currentTimeMillis(); clear(); Long d8 = System.currentTimeMillis(); updateString(count, commitlength); Long d9 = System.currentTimeMillis(); System.out.println("第一步清理耗时:" + (d2 - d1) + "ms"); System.out.println("第一次一般提交耗时:" + (d3 - d2) + "ms"); System.out.println("第二步清理耗时:" + (d4 - d3) + "ms"); System.out.println("第一次Prepared提交耗时:" + (d5 - d4) + "ms"); System.out.println("第二步清理耗时:" + (d6 - d5) + "ms"); System.out.println("第二次Prepared提交耗时:" + (d7 - d6) + "ms"); System.out.println("第三步清理耗时:" + (d8 - d7) + "ms"); System.out.println("第二次一般提交耗时:" + (d9 - d8) + "ms"); System.out.println("-----------------------------------------------"); } static void updateString(int count, int commitlength) throws SQLException { String sqlhead = "insert into ZH(zh,product,state) values"; Statement stmt = cn.createStatement(); int k = 0; for (int i = 0; i < count; i++) { k++; String zh = "zh" + i; String pro = "pro" + i; String state = "state" + i; StringBuilder sb = new StringBuilder(); sb.append(sqlhead).append(" ('").append(zh).append("','").append(pro).append("','").append(state).append("')"); stmt.addBatch(sb.toString()); if (k > commitlength) { k = 0; stmt.executeBatch(); cn.commit(); } } stmt.executeBatch(); cn.commit(); stmt.close(); } static void updatePrepared(int count, int commitlength) throws SQLException { PreparedStatement pstmt = cn.prepareStatement("insert into ZH(zh,product,state) values (?,?,?)"); int k = 0; for (int i = 0; i < count; i++) { k++; String zh = "zh" + i; String pro = "pro" + i; String state = "state" + i; pstmt.setString(1, zh); pstmt.setString(2, pro); pstmt.setString(3, state); pstmt.addBatch(); if (k > commitlength) { k = 0; pstmt.executeBatch(); cn.commit(); pstmt.clearBatch(); } } pstmt.executeBatch(); cn.commit(); pstmt.close(); } static void clear() throws SQLException { String sqlhead = "delete from ZH"; Statement stmt = cn.createStatement(); stmt.executeUpdate(sqlhead); cn.commit(); stmt.close(); }}// 从开始到最后, 我只有这一个 StringBuilder 对象, 每次生成一条SQL, 数据库执行时却插入了多条, 然后又开始拼接 SQL...StringBuilder sql = new StringBuilder();String str = "INSERT INTO T_USERINFO(CREATE_TIME, ID) VALUES ";sql.append(str);for (int i = 1; i < (num + 1); i++) {// 要保证公平, 也在循环中 new 对象user = new UserInfo();sql.append("('").append(user.getCreateTime());sql.append("', '");sql.append(user.getId()).append("'),");if (i % 50 == 0) {// 执行并提交至数据库. 只执行一条 SQL, 结果却会在数据库插入多条数据.// 并没有使用 addbatch! addbatch 时使用预编译, 这一点我还是知道的...st.execute(sql.deleteCharAt(sql.length() - 1).toString());conn.commit();// 重新开始拼接字符串sql.delete(str.length(), sql.length());}}st.execute(sql.deleteCharAt(sql.length() - 1).toString());conn.commit(); 30 楼 skzr.org 2011-05-09 最近做了个500万的数据测试——来源于真实数据:此表数据有3750多万条记录
hibernate查询时挂了(http://skzr-org.iteye.com/blog/1027791),不过对于其他操作在大数据量时建议还是不要用hibernate!
当找为什么jdbcTemplate RowMapper正确加载500W记录,而hibernate失败时发现hibernate还是产生了很多中间变量,所以内存极度不够了 31 楼 fmjsjx 2011-05-09 说穿了,在数据库插入操作时无论是hibernate还是jdbc,它的性能都取决于数据库的性能,二者没有太大差距。都说hibernate性能差,其实说的是查询,在做查询操作时hibernate的性能的确不咋地,从我使用的经验来看,碰到复杂的多表关联查询时hibernate的效率有时甚至不到jdbc的三分之一。所以,用hibernate还是jdbc取决于你的应用场景,hibernate适合于增、删、改操作较多、比较简单不是太复杂的数据库结构,如果你的应用需要大量的复杂的多表关联查询,还是用jdbc吧。 32 楼 liu.anxin 2011-05-09 fmjsjx 写道 插入操作时无论是hibernate还是jdbc,它的性能都取决于数据库的性能,二者没有太大差距。
没错... 33 楼 ppgunjack 2011-05-09 liu.anxin 写道fmjsjx 写道 插入操作时无论是hibernate还是jdbc,它的性能都取决于数据库的性能,二者没有太大差距。
没错...
应该说都是取决于jdbc driver的性能, 即使jdbc性能榨干了,实际数据库还是有很大余量干事的 34 楼 zwq4166506 2012-02-23 建议楼主用oracle测试,mysql批处理不咋的