Lucene Payload 的研究与应用(转)
Lucene 是最初是由 Douglass R. Cutting 博士发布在自己主页上的一个 Java 全文信息检索工具包,后来成为 Apache Jakarta 家族中的一个开源项目,目前已经成为 Apache 基金会的顶级项目。索引是现代搜索引擎的核心,建立索引的过程就是把源数据处理成方便查询的索引文件的过程。 Lucene 采用的是一种被称为倒排索引 (Inverted Index) 的机制,倒排索引也是大多现代搜索引擎的基础。
Payload (元数据) 诞生于 Lucene 的2.2 版本,它是在 Lucene 2.1 索引文件格式的基础上扩展而来,提供了一种可以灵活配置的高级索引技术。本文重点研究了 Payload 的实现原理、索引结构的变化、接口 API ,在本文的最后举例说明了 Payload 是如何帮助改善搜索体验的。
Payload 的出现
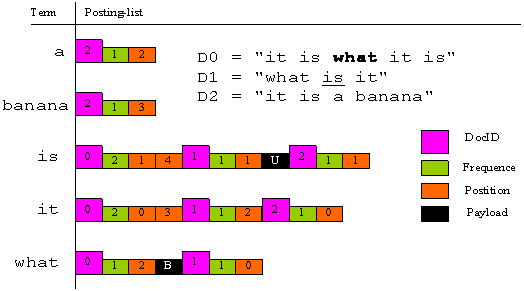
倒排索引就是说我们维护了一个词条表,对于这个表中的每个词条,都有一个链表描述了有哪些文档包含了这个词条。假定我们有三篇文档 D0,D1,D2:
?
那么,我们可以创建如下倒排索引结构:
回页首索引结构的变化
为了更加形象的描述改进后的索引结构,我们用不同的颜色表示出文档 ID ,词频,位置和 Payload,如图 1 所示,(U表示下划线,B表示粗体)
图 1:Lucene的索引结构对比 Lucene2.1 的索引结构,Lucene2.2 的索引结构的表达式如下:
如图2所示,以文档的?url?信息为例,通过为每一个文档构造一个特殊的词条 ”url” ,将每个文档的?ur?l值作为 payload 信息,把 Payload 与文档编号关联起来,这样就可以实现文档级的 Payload。
回页首
Payload 相关的 API
从 Lucene2.2 的索引结构可以看出,Payload 的存储与词条的位置信息是紧密联系在一起的,因此 Payload 的存储和检索 API 位于Token类和 TermPositions 类当中。
向词条中存储 Payload 信息
Payload 信息的构造函数从位置信息中检索 Payload回页首Payload 的应用场景举例
场景一:改进的 Lucene 的区间检索
日期检索是区间检索的常见例子,如用户需要在图书馆中检索特定年代的图书,满足如下条件:
场景二:提高特定词汇的评分
利用 Payload 功能,还可以提高文档中特定词汇的评分,如黑体词汇、斜体词汇等,从而优化搜索结果排序。
下面还以文档 D0 和 D1 为例说明如何设置和检索 Payload。
?
Step1:在?Analyzer?处理过程中,为特殊词汇添加评分?Payload
回页首总结
Payload 是 Lucene 一个允许在索引中为词条储存元数据信息。希望通过阅读本文,你可以对Payload 功能有一个整体的了解,进而可以灵活运用 Payload 的功能来优化具体的应用。
?