二、SOLR搭建企业搜索平台【中文分词】
这篇文章,主要说的是怎么在solr中加入中文分词:
??? 1、下载分词器:http://code.google.com/p/mmseg4j/
??? 2、将解压后的mmseg4j-1.8.2目录下的mmseg4j-all-1.8.2.jar拷贝到Tomcat _HOME\webapps\solr\WEB-INF\lib目录下。
??? 3、添加词库:在C:\solr-tomcat\solr目录下新建dic文件夹,将解压后的sogou-dic\data目录下的words.dic拷贝到C:\solr-tomcat\solr\dic目录下。
??? 4、更改schema.xml(c:\solr-tomcat\solr\conf\)文件,使分词器起到作用。更改内容为:
<types> ……<!--mmseg4j field types--> <fieldType name="textComplex" positionIncrementGap="100" > <analyzer> <tokenizer mode="complex" dicPath="C:\solr-tomcat\solr\dic"/> <filter positionIncrementGap="100" > <analyzer> <tokenizer mode="max-word" dicPath="C:\solr-tomcat\solr\dic"/> <filter positionIncrementGap="100" > <analyzer> <tokenizer mode="simple" dicPath="C:\solr-tomcat\solr\dic"/> <filter name="code"><fields>……<field name="simple" type="textSimple" indexed="true" stored="true" multiValued="true"/> <field name="complex" type="textComplex" indexed="true" stored="true" multiValued="true"/> <field name="text" type="textMaxWord" indexed="true" stored="true" multiValued="true"/>……</fields>?
<copyField source="simple" dest="text"/><copyField source="complex" dest="text"/>?
重启你的tomcat 。
访问:http://localhost:8089/solr/admin/analysis.jsp可以看 mmseg4j 的分词效果。在 Field 的下拉菜单选择 name,然后在应用输入 complex。分词的结果,如下图: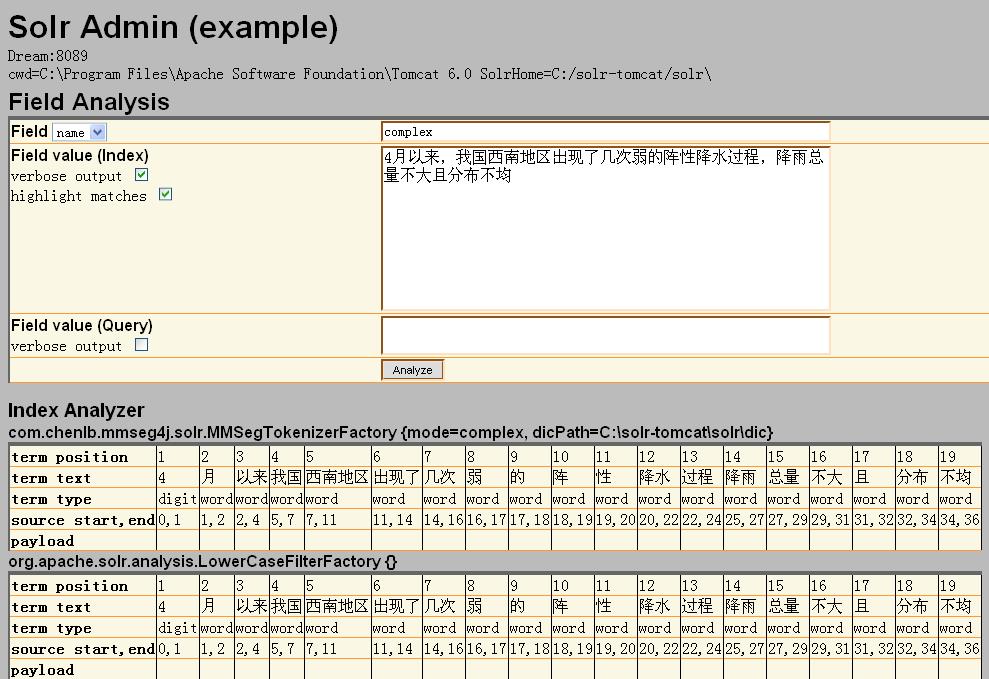
?呵呵,可以运行起来了,那就添加个文档试试吧,在解压后的apache-solr-1.4.0\example\exampledocs目录下创建 mmseg4j-solr-demo-doc.xml 文档,内容如下:
<add> <doc> <field name="id">1</field> <field name="text">昨日,记者从解放军总参谋部相关部门获悉,截至3月28日,解放军和武警部队累计出动7.2万人次官兵支援地方抗旱救灾。组织民兵预备役人员20.2万人 次支援地方抗旱救灾。</field> </doc> <doc> <field name="id">2</field> <field name="text">下半年房价调整就是挤水分 房价回不到去年水平。</field> </doc> <doc> <field name="id">3</field> <field name="text">solr是基于Lucene Java搜索库的企业级全文搜索引擎,目前是apache的一个项目。</field> </doc> <doc> <field name="id">4</field> <field name="text">中国人民银行是中华人民共和国的中央银行。</field> </doc> </add>
?然后在 cmd 下运行 post.jar,如下:
F:\lucene\solr\apache-solr-1.4.0\example\exampledocs>java -Durl=http://localhost:8089/solr/update -Dcommit=yes -jar post.jar mmseg4j-solr-demo-doc.xml? (注意:F:\lucene\solr 要根据你自己的实际情况而定)
?
查看是否有数据,访问:http://localhost:8089/solr/admin/ 在Query String: 中输入“中国”,显示如下图所示:
呵呵,成功了。至于schema.xml中的配置属性会在下一章中进行详细的介绍。
?
[Solr分词顺序]
Solr建立索引和对关键词进行查询都得对字串进行分词,在向索引库中添加全文检索类型的索引的时候,Solr会首先用空格进行分词,然后把分词结果依次使用指定的过滤器进行过滤,最后剩下的结果才会加入到索引库中以备查询。分词的顺序如下:
索引
1:空格whitespaceTokenize
2:过滤词(停用词,如:on、of、a、an等) StopFilter
3:拆字WordDelimiterFilter
4:小写过滤LowerCaseFilter
5:英文相近词EnglishPorterFilter
6:去除重复词RemoveDuplicatesTokenFilter
查询
1:查询相近词
2:过滤词
3:拆字
4:小写过滤
5:英文相近词
6:去除重复词
以上是针对英文,中文的除了空格,其他都类似