关于高并发写数据的性能优化提升的思考和实践
【背景】由于公司业务的需要,需要开发一个消息转发服务器,总体需求大致为:要求每秒的接入能力不低于1000,需要做数据统计(重点),数据不能缓存,尽可能快的转发,延时尽可能的低,可以允许丢失一些消息。
?
?按照设计规格,每秒产生的统计数据不低于1000,这些数据需要入库,提供给报表做分析。因此,对统计数据t_statistics这表来说,并发写的鸭梨很大。由于要求尽可能的低延时,因此,每一个服务接入线程单独的存储统计数据也不现实:使用数据库线程池或者单线程直接存储都会对延时(需要对请求端有应答)有较大影响。 大致的数据流图如下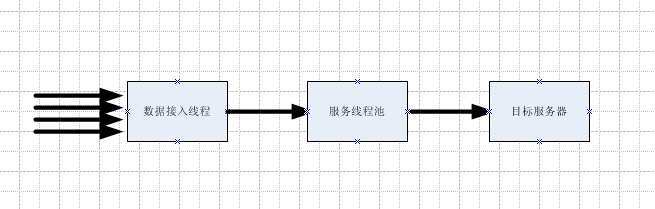
?
????? 数据库使用的是mysql5.5 最终部署OS为linux2.6,对于mysql,经过测试,单线程单表每秒写入1300是比较稳定的速率,因此,基于要高于设计规格的思想,接入速率也要高于1000。那么问题来了-----对于每秒产生1000条统计数据应该如何插入数据库呢?每个服务线程中单独插入肯定不现实,因为这要维持一个庞大的数据库线程池,或者排队,带来的是延迟。
?
????? 既然接入速率和存储速率能够匹配,因此,换个角度考虑的话,这就是个很基本的? 生产者---消费者模型,上文中已经提到,单个线程的写入能力已经能达到要求,因此,重点是协调 N---1 模型的并发竞争。
?
??????基于N---1 的生产者---消费者模型,或者消费者比较少的模型,一个很重要的点在于如何通知消费者消费数据。太频繁的通知将带来消费低效,毕竟线程切换是需要付出代价的,因此,批次的概念在这里被很好的运用了。
?
????? 基于一个批次的存储,也就是当生产者发现一个批次的数据达到一定的阀值时候,通知消费者来消费当前这个批次,问题又来了:当消费者消费某个批次的数据时候,生产者最新生产的数据应该怎么办呢,如果消费者---生产者基于共享队列(链表)的话,将会频繁的上锁、解锁和通知,这对编程来讲也带来复杂度。
?
????? 实际上,上文中已经提到,当一个批次满的时候,就应该通知消费者写数据库,那么在消费者消费数据的空档期,新产生的数据仍然应该能够快速的消费掉,至少不能让消费者多等,那么是否能再开辟一个批次呢?
?
????? OK,N---1 的消费者--生产者模型基本出来了,基于多个链表的缓冲区,消费者集中向一个链表中写数据,当当前链表数据满时,通知消费者消费,后面的消费者开始切换链表,使用新的空的链表来存储数据。
?
????? 在个人开发的消息转发服务器中,使用了6个List,阀值配置的是1w,也是就是当某个List的size达到1w的时候,就开始切换,聪明的你也许很快就想到了,瓶颈会再次出现在 List 切换的时候,实际上这个可以不算是问题,因为使用了多个List,在特定的时候哪些List是可用的,哪些List是消费者应该消费的,这些需要建立索引, 建立索引的好处是公平、避免单个队列数据过大和通知遗漏。
???
???? 基于以上一些分析,个人写了如下的一点代码,使用了泛型,可通用。
????
?
???? 如下是spring的配置
????
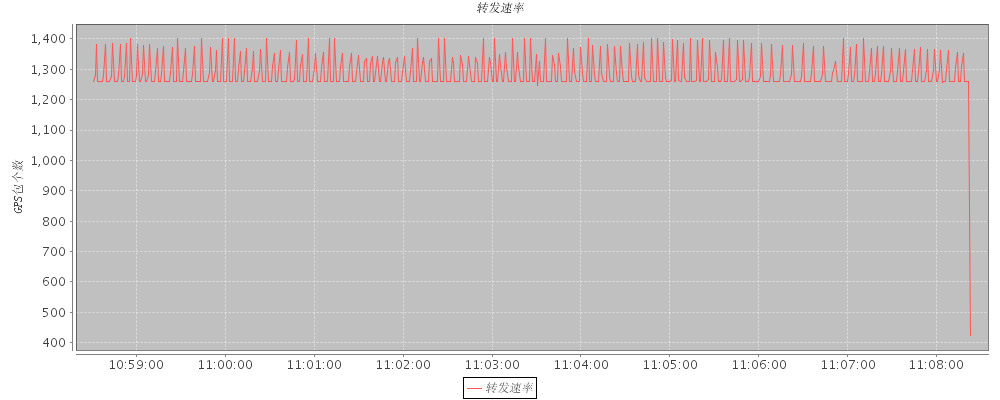
?? 经过严密的测试,接入速率为 1.3K---1.4K 的时候,数据库操作比较稳定,如下图
?
?
?? 上图是对转发数据的统计做的一个简单图表,实际上由于不能做到发送速率稳定,因此上图的数据会有一些波动,但是没有丢包。
?
??? 也许,你会认为,如果请求数要高于1.4,那么数据库瓶颈就出来了呀,对,你可以考虑增加一个消费线程,但是这样做存储效率会提升但是不会翻番的。对于一个系统,是有最大负载的,都会有瓶颈的,超出部分,应该勇敢 say no.
?
??? 欢迎拍砖!
?
?????
?
?
?
?