servlet 输出中文显示为问号"??"的解决办法
这个问题解决办法很简单:
?
将 doGet或doPost的
response.setContentType("text/html");
增加一点点内容
response.setContentType("text/html;charset=gb2312"); 或者改为response.setContentType("text/html;charset=GBK");?
?
?
?
?
有关Java中文问题分析 可以参见老唐的一篇文章。具体出自:http://www.360doc.com/content/09/0320/07/14381_2860637.shtml
文章从实际的中文问题中,分析问题的根本原因,以及解决之道。
?
注意,本章虽然着重说明“中文问题”,但本章所推出的结论却是适合于世界所有语言文字的。
我们在实际开发中碰到的中文问题,真是形形色色,无法一一列举。但是它们不是随机产生的,而是有规律可循,有办法解决的。
我们碰到最多的中文问题,都发生在使用Java Servlet写WEB应用时。其次,使用Java Mail API发送e-mail也会有类似的问题。从表象上区分,大致上有以下几种:
- 好端端的中文显示成了问号“?”,且一个中文变成2个问号。
- 好端端的中文显示成了问号“?”,且一个中文变成1个问号。
- 好端端的中文显示成了看不懂的符号,如“?ò°?Alibaba”。
- WEB页面中部分中文显示正常,部分中文是乱码。
要分析这些问题的根本原因,首先要了解这些中文字符的输入源,其次是了解这些字符被输出到用户浏览器经过了哪些转换和输出环节。中文字符可以来源于:
- 程序内嵌的中文,我们在程序里直接书写中文字符串。
- 文本文件,利用XML文件,利用XML解析器读入内存。
- 数据库,利用SQL查询,取得的结果。
- 模板文件,例如Velocity或WebMacro模板,我们使用模板生成WEB页面。
- JSP页面,在JSP生成的WEB页面。
- 用户通过浏览器提交的表单。
中文字符被装入内存以后,还要经过若干个转换和输出环节,最后才能到达用户的浏览器被用户看到。
- 文本通过浏览器读取服务器的HTTP响应,并将响应中包含的HTML页面显示在浏览器上。
- 文本可能被写入XML文件、文本文件、数据库中。
以上列举的任何一个环节发生错误,都可能产生“乱码”现象。因此发生乱码现象时,不要慌,想想这个乱码的文本是从哪里来的,又是以什么方式输出的。
字符的输入、转换、输出环节内嵌在程序代码中的中文因为Java源代码(用字节流方式 —— 输出到字符流方式 —— 输出到首先检查HTTP响应中指定的content type,也就是servlet通过如果既没有在HTTP响应中指定字符编码,也没有在HTML内容中指定字符编码,则浏览器根据一定的规则自动确定页面的字符编码。例如,在英文环境中,浏览器会使用ISO-8859-1,简体中文环境中,则使用GBK。用户也可以根据自己的需要手工改变这一设置。 其它输出环节
文本还可能被写入XML文件、文本文件、数据库中。类似的,输出文件时一般都要指定字符编码。如果不指定,通常Java会选择系统默认的编码。这为程序运行的结果产生了不确定因素。
“乱码”分析明白了各输入、转换、输出环节是怎样工作的,我们的分析工作就有头绪了。在深入分析之前,有不少情况,观察乱码的表面现象就可以得到大概的结论。
一个中文变成了两个问号“?”这个现象通常表明字符在输入时出错,也就是解码错误。
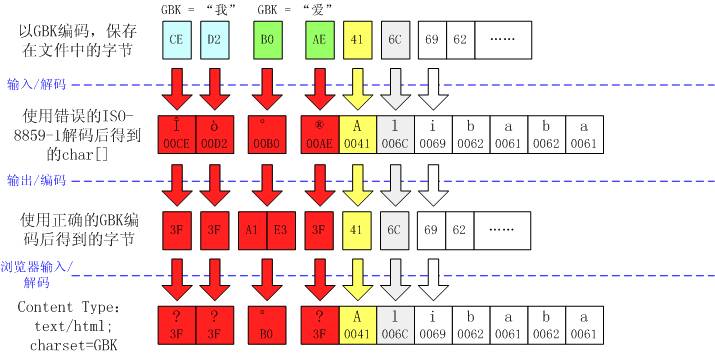
?
虽然输出编码是对的,但在此之前,由于错误的输入编码,每个中文字变成了两个不相干的欧洲字符。而这些欧洲字符的编码和GBK编码是相冲突的(但也不一定完全冲突,例如上例中的第三个字节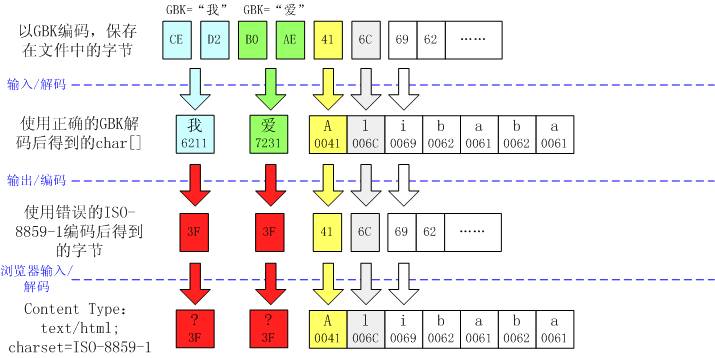
?
这很可能是因为没有设置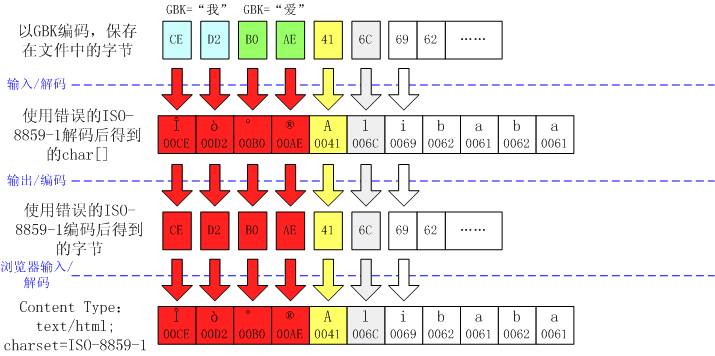
?
明眼人一看就发现,实际上在这种情况下,最后输出到浏览器上的字节流是正确的!只是因为content type被设成了错误的ISO-8859-1编码,所以才导致浏览器显示不正确的。事实上,用户可以手工改变浏览器的设置,使浏览器使用GBK对字节流重新解码。
看起来象是数学中的“负负得正”。为什么会这样呢?这是因为ISO-8859-1编码的特殊性导致的。ISO-8859-1字符集的编码范围是输入环节 —— 如果我们不指定模板系统的字符编码,那么,Java会使用系统默认的编码(ISO-8859-1)读入模板文件,从而将一个GBK中文编码看作两个欧洲字符。
Content Type
浏览器环境
服务器环境
从模板取得的中文字
从XML取得的中文字
从用户表单取得的中文字
深入分析
以上只是分析了最常见的“乱码”现象。实际上,还可能会发生更复杂一点的情形。但是无论什么情形,都可以通过仔细分析中文字符经过的每一个输入、转换、输出环节,来了解它的原因。
?