面试题--海量数据
?
,然后根据所取得的值将url分别存储到1000个小文件(记为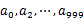 )中。这样每个小文件的大约为300M。遍历文件b,采取和a相同的方式将url分别存储到1000小文件中(记为
)中。这样每个小文件的大约为300M。遍历文件b,采取和a相同的方式将url分别存储到1000小文件中(记为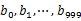 )。这样处理后,所有可能相同的url都在对应的小文件(
)。这样处理后,所有可能相同的url都在对应的小文件(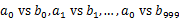 )中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。求每对小文件中相同的url时,可以把其中一个小文件的url存储到hash_set中。然后遍历另一个小文件的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了。
)中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。求每对小文件中相同的url时,可以把其中一个小文件的url存储到hash_set中。然后遍历另一个小文件的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了。??? 方案2:如果允许有一定的错误率,可以使用Bloom filter,4G内存大概可以表示340亿bit。将其中一个文件中的url使用Bloom filter映射为这340亿bit,然后挨个读取另外一个文件的url,检查是否与Bloom filter,如果是,那么该url应该是共同的url(注意会有一定的错误率)。
??? 读者反馈@)中。这样新生成的文件每个的大小大约也1G(假设hash函数是随机的)。找一台内存在2G左右的机器,依次对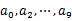 用hash_map(query, query_count)来统计每个query出现的次数。利用快速/堆/归并排序按照出现次数进行排序。将排序好的query和对应的query_cout输出到文件中。这样得到了10个排好序的文件(记为
用hash_map(query, query_count)来统计每个query出现的次数。利用快速/堆/归并排序按照出现次数进行排序。将排序好的query和对应的query_cout输出到文件中。这样得到了10个排好序的文件(记为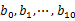 )。对
)。对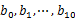 这10个文件进行归并排序(内排序与外排序相结合)。
这10个文件进行归并排序(内排序与外排序相结合)。
方案2:
??? 一般query的总量是有限的,只是重复的次数比较多而已,可能对于所有的query,一次性就可以加入到内存了。这样,我们就可以采用trie树/hash_map等直接来统计每个query出现的次数,然后按出现次数做快速/堆/归并排序就可以了
??? (读者反馈@店小二:原文第二个例子中:“找一台内存在2G左右的机器,依次对用hash_map(query, query_count)来统计每个query出现的次数。”由于query会重复,作为key的话,应该使用hash_multimap 。hash_map 不允许key重复。此反馈是否正确,待日后考证)。
方案3:
??? 与方案1类似,但在做完hash,分成多个文件后,可以交给多个文件来处理,采用分布式的架构来处理(比如MapReduce),最后再进行合并。
3. 有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
??? 方案1:顺序读文件中,对于每个词x,取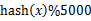 ,然后按照该值存到5000个小文件(记为
,然后按照该值存到5000个小文件(记为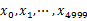 )中。这样每个文件大概是200k左右。如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M。对每个小文件,统计每个文件中出现的词以及相应的频率(可以采用trie树/hash_map等),并取出出现频率最大的100个词(可以用含100个结点的最小堆),并把100词及相应的频率存入文件,这样又得到了5000个文件。下一步就是把这5000个文件进行归并(类似与归并排序)的过程了。
)中。这样每个文件大概是200k左右。如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M。对每个小文件,统计每个文件中出现的词以及相应的频率(可以采用trie树/hash_map等),并取出出现频率最大的100个词(可以用含100个结点的最小堆),并把100词及相应的频率存入文件,这样又得到了5000个文件。下一步就是把这5000个文件进行归并(类似与归并排序)的过程了。
4. 海量日志数据,提取出某日访问百度次数最多的那个IP。
??? 方案1:首先是这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中。注意到IP是32位的,最多有2^32个IP。同样可以采用映射的方法,比如模1000,把整个大文件映射为1000个小文件,再找出每个小文中出现频率最大的IP(可以采用hash_map进行频率统计,然后再找出频率最大的几个)及相应的频率。然后再在这1000个最大的IP中,找出那个频率最大的IP,即为所求。
5. 在2.5亿个整数中找出不重复的整数,内存不足以容纳这2.5亿个整数。
??? 方案1:采用2-Bitmap(每个数分配2bit,00表示不存在,01表示出现一次,10表示多次,11无意义)进行,共需内存2^32*2bit=1GB内存,还可以接受。然后扫描这2.5亿个整数,查看Bitmap中相对应位,如果是00变01,01变10,10保持不变。所描完事后,查看bitmap,把对应位是01的整数输出即可。
??? 方案2:也可采用上题类似的方法,进行划分小文件的方法。然后在小文件中找出不重复的整数,并排序。然后再进行归并,注意去除重复的元素。
6. 海量数据分布在100台电脑中,想个办法高效统计出这批数据的TOP10。
方案1:
- 在每台电脑上求出TOP10,可以采用包含10个元素的堆完成(TOP10小,用最大堆,TOP10大,用最小堆)。比如求TOP10大,我们首先取前10个元素调整成最小堆,如果发现,然后扫描后面的数据,并与堆顶元素比较,如果比堆顶元素大,那么用该元素替换堆顶,然后再调整为最小堆。最后堆中的元素就是TOP10大。求出每台电脑上的TOP10后,然后把这100台电脑上的TOP10组合起来,共1000个数据,再利用上面类似的方法求出TOP10就可以了。
(更多可以参考:第三章、寻找最小的k个数,以及第三章续、Top K算法问题的实现)
??? 读者反馈@,求着n个实数在实轴上向量2个数之间的最大差值,要求线性的时间算法。
方案1:最先想到的方法就是先对这n个数据进行排序,然后一遍扫描即可确定相邻的最大间隙。但该方法不能满足线性时间的要求。故采取如下方法:
- 找到n个数据中最大和最小数据max和min。用n-2个点等分区间[min, max],即将[min, max]等分为n-1个区间(前闭后开区间),将这些区间看作桶,编号为
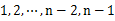 ,且桶i 的上界和桶i+1的下届相同,即每个桶的大小相同。每个桶的大小为:
,且桶i 的上界和桶i+1的下届相同,即每个桶的大小相同。每个桶的大小为: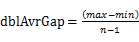 。实际上,这些桶的边界构成了一个等差数列(首项为min,公差为
。实际上,这些桶的边界构成了一个等差数列(首项为min,公差为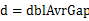 ),且认为将min放入第一个桶,将max放入第n-1个桶。将n个数放入n-1个桶中:将每个元素x[i] 分配到某个桶(编号为index),其中
),且认为将min放入第一个桶,将max放入第n-1个桶。将n个数放入n-1个桶中:将每个元素x[i] 分配到某个桶(编号为index),其中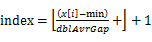 ,并求出分到每个桶的最大最小数据。最大间隙:除最大最小数据max和min以外的n-2个数据放入n-1个桶中,由抽屉原理可知至少有一个桶是空的,又因为每个桶的大小相同,所以最大间隙不会在同一桶中出现,一定是某个桶的上界和气候某个桶的下界之间隙,且该量筒之间的桶(即便好在该连个便好之间的桶)一定是空桶。也就是说,最大间隙在桶i的上界和桶j的下界之间产生j>=i+1。一遍扫描即可完成。
,并求出分到每个桶的最大最小数据。最大间隙:除最大最小数据max和min以外的n-2个数据放入n-1个桶中,由抽屉原理可知至少有一个桶是空的,又因为每个桶的大小相同,所以最大间隙不会在同一桶中出现,一定是某个桶的上界和气候某个桶的下界之间隙,且该量筒之间的桶(即便好在该连个便好之间的桶)一定是空桶。也就是说,最大间隙在桶i的上界和桶j的下界之间产生j>=i+1。一遍扫描即可完成。16. 将多个集合合并成没有交集的集合
??? 给定一个字符串的集合,格式如: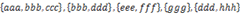 。要求将其中交集不为空的集合合并,要求合并完成的集合之间无交集,例如上例应输出
。要求将其中交集不为空的集合合并,要求合并完成的集合之间无交集,例如上例应输出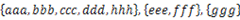 。
。
(1) 请描述你解决这个问题的思路;
(2) 给出主要的处理流程,算法,以及算法的复杂度;
(3) 请描述可能的改进。
??? 方案1:采用并查集。首先所有的字符串都在单独的并查集中。然后依扫描每个集合,顺序合并将两个相邻元素合并。例如,对于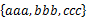 ,首先查看aaa和bbb是否在同一个并查集中,如果不在,那么把它们所在的并查集合并,然后再看bbb和ccc是否在同一个并查集中,如果不在,那么也把它们所在的并查集合并。接下来再扫描其他的集合,当所有的集合都扫描完了,并查集代表的集合便是所求。复杂度应该是O(NlgN)的。改进的话,首先可以记录每个节点的根结点,改进查询。合并的时候,可以把大的和小的进行合,这样也减少复杂度。
,首先查看aaa和bbb是否在同一个并查集中,如果不在,那么把它们所在的并查集合并,然后再看bbb和ccc是否在同一个并查集中,如果不在,那么也把它们所在的并查集合并。接下来再扫描其他的集合,当所有的集合都扫描完了,并查集代表的集合便是所求。复杂度应该是O(NlgN)的。改进的话,首先可以记录每个节点的根结点,改进查询。合并的时候,可以把大的和小的进行合,这样也减少复杂度。
17. 最大子序列与最大子矩阵问题
数组的最大子序列问题:给定一个数组,其中元素有正,也有负,找出其中一个连续子序列,使和最大。
??? 方案1:这个问题可以动态规划的思想解决。设b[i]表示以第i个元素a[i]结尾的最大子序列,那么显然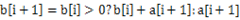 。基于这一点可以很快用代码实现。
。基于这一点可以很快用代码实现。
最大子矩阵问题:给定一个矩阵(二维数组),其中数据有大有小,请找一个子矩阵,使得子矩阵的和最大,并输出这个和。
??? 方案2:可以采用与最大子序列类似的思想来解决。如果我们确定了选择第i列和第j列之间的元素,那么在这个范围内,其实就是一个最大子序列问题。如何确定第i列和第j列可以词用暴搜的方法进行。
?
第二部分、海量数据处理之Bti-map详解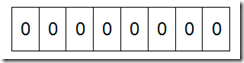
?????
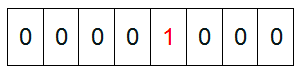
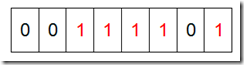
然后我们现在遍历一遍Bit区域,将该位是一的位的编号输出(2,3,4,5,7),这样就达到了排序的目的。下面的代码给出了一个BitMap的用法:排序。
view plain- //定义每个Byte中有8个Bit位??#include?<memory.h>??
- #define?BYTESIZE?8??void?SetBit(char?*p,?int?posi)??
- {??????for(int?i=0;?i?<?(posi/BYTESIZE);?i++)??
- ????{??????????p++;??
- ????}????
- ????*p?=?*p|(0x01<<(posi%BYTESIZE));//将该Bit位赋值1??????return;??
- }????
- void?BitMapSortDemo()??{??
- ????//为了简单起见,我们不考虑负数??????int?num[]?=?{3,5,2,10,6,12,8,14,9};??
- ??????//BufferLen这个值是根据待排序的数据中最大值确定的??
- ????//待排序中的最大值是14,因此只需要2个Bytes(16个Bit)??????//就可以了。??
- ????const?int?BufferLen?=?2;??????char?*pBuffer?=?new?char[BufferLen];??
- ??????//要将所有的Bit位置为0,否则结果不可预知。??
- ????memset(pBuffer,0,BufferLen);??????for(int?i=0;i<9;i++)??
- ????{??????????//首先将相应Bit位上置为1??
- ????????SetBit(pBuffer,num[i]);??????}??
- ??????//输出排序结果??
- ????for(int?i=0;i<BufferLen;i++)//每次处理一个字节(Byte)??????{??
- ????????for(int?j=0;j<BYTESIZE;j++)//处理该字节中的每个Bit位??????????{??
- ????????????//判断该位上是否是1,进行输出,这里的判断比较笨。??????????????//首先得到该第j位的掩码(0x01<<j),将内存区中的??
- ????????????//位和此掩码作与操作。最后判断掩码是否和处理后的??????????????//结果相同??
- ????????????if((*pBuffer&(0x01<<j))?==?(0x01<<j))??????????????{??
- ????????????????printf("%d?",i*BYTESIZE?+?j);??????????????}??
- ????????}??????????pBuffer++;??
- ????}??}??
- ??int?_tmain(int?argc,?_TCHAR*?argv[])??
- {??????BitMapSortDemo();??
- ????return?0;??}??
可进行数据的快速查找,判重,删除,一般来说数据范围是int的10倍以下
基本原理及要点
使用bit数组来表示某些元素是否存在,比如8位电话号码
扩展
Bloom filter可以看做是对bit-map的扩展(关于Bloom filter,请参见:海量数据处理之Bloom filter详解)。
问题实例
1)已知某个文件内包含一些电话号码,每个号码为8位数字,统计不同号码的个数。
??? 8位最多99 999 999,大概需要99m个bit,大概10几m字节的内存即可。 (可以理解为从0-99 999 999的数字,每个数字对应一个Bit位,所以只需要99M个Bit==1.2MBytes,这样,就用了小小的1.2M左右的内存表示了所有的8位数的电话)
2)2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。
??? 将bit-map扩展一下,用2bit表示一个数即可,0表示未出现,1表示出现一次,2表示出现2次及以上,在遍历这些数的时候,如果对应位置的值是0,则将其置为1;如果是1,将其置为2;如果是2,则保持不变。或者我们不用2bit来进行表示,我们用两个bit-map即可模拟实现这个2bit-map,都是一样的道理。
参考:
- http://www.cnblogs.com/youwang/archive/2010/07/20/1781431.html。http://blog.redfox66.com/post/2010/09/26/mass-data-4-bitmap.aspx。
完。
分享到: