将HashMap文件化
???( 只是个想法加雏形,实现的很丑陋且效率很低下)
??? 有这样一种场景,校验千万行文本中某一列键值(长度30以上)的唯一性(要求100%准确)。按我的水平,自然就想到用HashMap,可这样就会将所有的键值都放入内存,对内存资源需求较大。然后我就想,数据库也有一样的需求呀,人家怎么搞的呢?思前想后,能力太有限,没思路。最后只能想到,如果把HashMap的存储介质由内存转移到外存(文件中),貌似会节省相当部分的内存(此假设未经证实)。于是着手改造,HashMap实现的主要算法基本了解只是对于寻址那块要从内存转入文件,这是关键。由此做了如下设计:
?
HashMap的put方法中:
由hashcode算出在table中的位置i,然后以table[i]为链首存储元素。
?
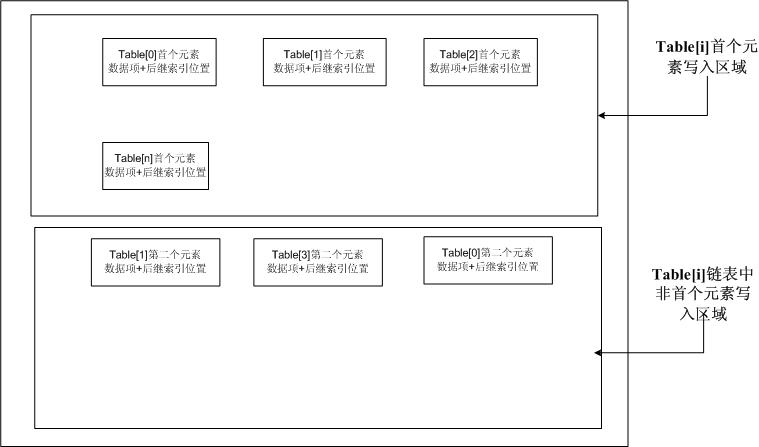
我的思路:
建一个索引文件,每个索引的结构:数据项+后继索引位置。索引长度:数据项长度+long型的长度(8字节)
table[i]即链首的位置 = i * 数据项长度+8
当首次写入链首时,索引位置埴0,因为下一个元素未知嘛。
当table[i]第n个元素写入时,从链首开始遍历(取后继索引位置,跳转至该位置),直到遍历索引位置为0的链表元素,将要写入第n个元素的文件位置记到此后继索引位置,并将第n个元素写入文件。如果遍历时发现,当前元素数据项与要写入元素的数据项值相同,则发现重复元素。
?
?
?
目前的问题:
1. io操作过多,考虑是不是可以通过内存映像文件来提高提高效率。当然加加cache也行,就是没考虑好怎么加。
2. 还木有想到。。。
?
?
上传了我丑陋的代码,运行FileMap就好。?
?
试用了一下jdbm-2.0.jar这个包,100万行数据插入,就是从1到100万,10行一提交。共用了38秒。使用内存14M左右,太NB。严重鄙视我提交的烂代码。
13 楼 mtnt2008 2011-04-20准备实现自己的想法,写一个。到时欢迎大家拍砖 @-@ 14 楼 lenozhi 2011-04-20 JE帐号 写道我的印象里java的io操作是比较弱的,文件操作性能很差.
所以说,新拿到一个值,虽然你可以算出来应该在什么位置,并用skip直接定位过去,可是在io内部还是给read中间哪些值. 再说,你向文件里插入一个值,我印象是不可能向链表似的前后改下索引就行了,好像给整个复制....
用RandomAccessFile可以实现我描述的(已经实现了)。
JE帐号 写道
反正,我以前用io的时候就是这个印象.
所以我一直觉得数据库应该对于文件系统的操作进行了底层的控制,比如从10000跳到20000,他是直接跳过去找到,而不是顺序读过去的.
数据库底层很可能是跳过文件系统,直接玩的。
15 楼 lenozhi 2011-04-20 mtnt2008 写道lenozhi 写道kimmking 写道直接用hashcode呗。
咋叫直接用hashcode,两个键值的hashcode相同咋办
hash冲突的处理方法:1.开放地址法 2.地址链法 3.再hash发
以前的一个思路:
1.把value通过MappedByteBuffer(java的内存文件映射)存入硬盘得到文件偏移量d;
2.对key做hash,以这个值为index,进行操作:桶数组[index] = d
3.如果发生hash冲突,选用一个处理hash冲突的方法
目前我用用RandomAccessFile整的,正要试试MappedByteBuffer。再配合加些cache,不知道能搞成啥样。 16 楼 ppgunjack 2011-04-20 索引大多都是B+树,可以保证分布平均,树深度不深,hash最坏的情况全落一个桶,唯一肯定是需要排序的,千万这个量不用纠结,与其考虑算法,应该优先考虑记录减肥降低磁盘io
17 楼 lenozhi 2011-04-20 ppgunjack 写道索引大多都是B+树,可以保证分布平均,树深度不深,hash最坏的情况全落一个桶,唯一肯定是需要排序的,千万这个量不用纠结,与其考虑算法,应该优先考虑记录减肥降低磁盘io
原来是这样子,学习了。 18 楼 咖啡豆子 2011-04-20 首先看你的KEY是什么特点,设定一个规则,将HASHMAP分散到多个文件。不过我觉得这么搞还不如就放在数据库里好了 19 楼 ppgunjack 2011-04-20 数据库是可以越过系统调用直接操纵磁盘,不过很多应用还是会架在OS的文件系统上访问数据
其实考虑类似bdb这样的嵌入式数据库比自己写类似应用要更容易,适用范围保护也更好,结合OS的内存虚拟磁盘使用可以很灵活构建方案 20 楼 real_aaron 2011-04-20 <p>如果不想重造轮子的话可以考虑使用oracle的 bdb je,其collections框架提供了map的持久化实现。 其中的 com.sleepycat.collections.StoredMap 应该能满足你的需要,要注意的是je是dual licence.</p>
<p>?</p> 21 楼 shguan2010 2011-04-20 考虑一下 jdbm2
http://code.google.com/p/jdbm2/ 22 楼 lenozhi 2011-04-20 shguan2010 写道考虑一下 jdbm2
http://code.google.com/p/jdbm2/
不错的东东 23 楼 uin57 2011-04-21 lenozhi 写道shguan2010 写道考虑一下 jdbm2
http://code.google.com/p/jdbm2/
不错的东东
为什么不试一下derby呢? 24 楼 renwolang521 2011-04-21 看你这个HashMap文件化,我想是否可以遍历一遍,存到sqlite中然后利用数据库寻找重复的。
java使用sqlite 就一个jar包(http://www.zentus.com/sqlitejdbc/)就行了,最后形成的也就一个文件。用完文件直接删了就行了。
25 楼 lenozhi 2011-04-21 renwolang521 写道看你这个HashMap文件化,我想是否可以遍历一遍,存到sqlite中然后利用数据库寻找重复的。
java使用sqlite 就一个jar包(http://www.zentus.com/sqlitejdbc/)就行了,最后形成的也就一个文件。用完文件直接删了就行了。
不错,我去试试。看看对大数据量的支持如何 26 楼 lenozhi 2011-04-21 试用了一下jdbm-2.0.jar这个包,100万行数据插入,就是从1到100万,10行一提交。共用了38秒。使用内存14M左右,太NB。严重鄙视我提交的烂代码。 27 楼 ray_linn 2011-04-21 bloom过滤器 28 楼 sx011966 2011-04-21 把那个文本作为oracle 外部表,然后用sql来排除 29 楼 iamlotus 2011-04-22 你这行事先知道吗?
知道的话遍历一遍,把hash相同的在内存里比较不就完了?
不知道就学数据库建B+树,用file based hash空间太大,肯定不合算。其实不用那么麻烦,建张表,建个UK,然后全部insert进去不就完了?千万而已,又不是千亿,数据库吃得消。
30 楼 lenozhi 2011-04-23 iamlotus 写道你这行事先知道吗?
知道的话遍历一遍,把hash相同的在内存里比较不就完了?
遍历一遍得把所有的hash值都存下来是吧,不然咋知道有hash相同的?这值到是可以把value设成空,可以节省内存空间。嗯。。等下,遍历一遍貌似得两个循环吧,不然咋找?
iamlotus 写道
不知道就学数据库建B+树,用file based hash空间太大,肯定不合算。其实不用那么麻烦,建张表,建个UK,然后全部insert进去不就完了?千万而已,又不是千亿,数据库吃得消。
用数据库整到是没试过,千万的话,字符串长度32,得多长时间?比如是个8核,64G的机器。
31 楼 iamlotus 2011-04-25 lenozhi 写道iamlotus 写道你这行事先知道吗?
知道的话遍历一遍,把hash相同的在内存里比较不就完了?
遍历一遍得把所有的hash值都存下来是吧,不然咋知道有hash相同的?这值到是可以把value设成空,可以节省内存空间。嗯。。等下,遍历一遍貌似得两个循环吧,不然咋找?
iamlotus 写道
不知道就学数据库建B+树,用file based hash空间太大,肯定不合算。其实不用那么麻烦,建张表,建个UK,然后全部insert进去不就完了?千万而已,又不是千亿,数据库吃得消。
用数据库整到是没试过,千万的话,字符串长度32,得多长时间?比如是个8核,64G的机器。
比如你有一组值A[]={A1 A2 A1 A3}, hash后分别是 {H1,H1,H1,H2} (假设A1,A2hash相等)
你的需求究竟是 “已知A1,问A中是否有和A1相同的值” 还是 “已知A,问其中有哪些值出现了一次以上”?
前者就是事先知道这行,后者就是不知道这行。
对前者,事先由A1算出 H1,然后遍历一遍A即可,连HashSet都不用,怎么会要两个循环?
后者你自己试试就知道时间了,配置不同不一样的。我估计不出插入时间,不过select应该能在20秒搞定。 32 楼 lenozhi 2011-04-25 iamlotus 写道lenozhi 写道iamlotus 写道你这行事先知道吗?
知道的话遍历一遍,把hash相同的在内存里比较不就完了?
遍历一遍得把所有的hash值都存下来是吧,不然咋知道有hash相同的?这值到是可以把value设成空,可以节省内存空间。嗯。。等下,遍历一遍貌似得两个循环吧,不然咋找?
iamlotus 写道
不知道就学数据库建B+树,用file based hash空间太大,肯定不合算。其实不用那么麻烦,建张表,建个UK,然后全部insert进去不就完了?千万而已,又不是千亿,数据库吃得消。
用数据库整到是没试过,千万的话,字符串长度32,得多长时间?比如是个8核,64G的机器。
比如你有一组值A[]={A1 A2 A1 A3}, hash后分别是 {H1,H1,H1,H2} (假设A1,A2hash相等)
你的需求究竟是 “已知A1,问A中是否有和A1相同的值” 还是 “已知A,问其中有哪些值出现了一次以上”?
前者就是事先知道这行,后者就是不知道这行。
对前者,事先由A1算出 H1,然后遍历一遍A即可,连HashSet都不用,怎么会要两个循环?
后者你自己试试就知道时间了,配置不同不一样的。我估计不出插入时间,不过select应该能在20秒搞定。
是知道A,A存在于文件中。找出A中重复的。jdbm那个还不错,我试过。