如何实现随机分库
如何实现随机分库
?
一、为什么要分库
如果应用系统涉及到的所有读写都在一个DB库里操作,会造成单点问题,如果这个DB宕机,则会导致整个应用不可用。
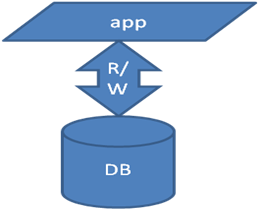
通过某种规则,将读写操作分散在多个DB库里,则可以规避单点问题
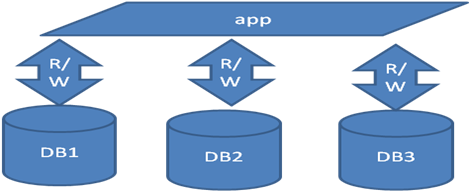
譬如DB1宕机,则只会影响数据流需要经过DB1的部分应用,而经过DB2和DB3的应用则不受任何影响。
?
二、分库规则
分库的规则有很多,譬如这样一个场景,需要将一条业务流水存储在DB里,该流水含有一个字段为用户ID,由16位数字组成。
现在假设总共有3个库,库编号分别为00、01、02,那么分库规则一般可以采用以下两种:
1、按特定规则分库:譬如根据用户ID的某一位对3取模,结果为0,则选择00库,为1,则选择01库,为2,则选择02库;
2、随机分库。
那么究竟哪种方案更好呢?
?
规则
优点
缺点
按特定规则分库
根据用户ID,能够确切知道这条流水会被存储在哪个分库里,因此非常适合需要根据用户ID查询流水的场景
随机分库
根据用户ID,不能够确定这个流水存储在哪个分库里。因此根据用户ID的查询,会涉及到跨多个库的查询。因此,查询可能会成为瓶颈
综上,对于那种需要高可用性,但没有精确查询需求的场景,采用随机分库是一个不错的选择;否则,则需要考虑特定规则的分库方案。
?
public class SqlMapClientTemplateManager implements InitializingBean{ /** 配置的数据源列表 */ private Map<String, DataSource> dataSourceMap; /** SqlMapClient使用的配置文件列表 */ private Resource[] configLocations; /**运行期可用的SqlMapClientTemplate */ private Map<String, SqlMapClientTemplate> sqlMapClientTemplates = new HashMap<String, SqlMapClientTemplate>(); /**运行期可用的数据源编号列表*/ private List<String> availableDsNos = new ArrayList<String>(); /** 获取运行期可用的数据源编号列表 */ public List<String> getAvailableDsNos(){ if(CollectionUtils.isEmpty(availableDsNos)){ throw new NoAvailableDataSourceException("没有可用的数据源"); } return new ArrayList<String>( availableDsNos); } /** 获取特定数据源编号对应的SqlMapClientTemplate */ public final SqlMapClientTemplate getSlaveSqlMapClientTemplate(String dsNo) { return slaveSqlMapClientTemplates.get(dsNo);}//初始化template,并放入缓存public void afterPropertiesSet(){ synchronized (this) { for (Map.Entry<String, DataSource> entry : dataSourceMap.entrySet()) { SqlMapClientTemplate sqlMapClientTemplate = constructSqlMapClientTemplate(entry.getValue()); if (null != sqlMapClientTemplate) { sqlMapClientTemplates.put(entry.getKey(), sqlMapClientTemplate); dsNos.add(entry.getKey()); } } } } /** * 根据数据源构造一个SqlMapClientTemplate实例 * @param dataSource 数据源 * @return SqlMapClientTemplate实例 */ private SqlMapClientTemplate constructSqlMapClientTemplate(DataSource dataSource) { SofaSqlMapClientFactoryBean sqlMapClientFactory = new SofaSqlMapClientFactoryBean(); sqlMapClientFactory.setDataSource(dataSource); sqlMapClientFactory.setConfigLocations(configLocations); SqlMapClientTemplate sqlMapClientTemplate = new SqlMapClientTemplate(); try { sqlMapClientFactory.afterPropertiesSet(); sqlMapClientTemplate.setSqlMapClient((SqlMapClient) sqlMapClientFactory.getObject()); sqlMapClientTemplate.afterPropertiesSet(); } catch (Exception e) { logger.error("根据数据源配置构造SqlMapClientTemplate实例发生异常", e); return null; } return sqlMapClientTemplate; }?
<bean id="sqlMapClientTemplateManager" ref="dataSourceMap"/><property name="configLocations"><list> <value>classpath:sqlmap/sqlmap.xml</value> </list> </property></bean><util:map id="dataSourceMap" map-value-ref="dataSource0"/><entry key="1" value-ref="dataSource1"/><entry key="2" value-ref="dataSource2"/></util:map>?
/** * 随机插入器 * 选择数据源时,从当前可用的数据源列表中进行选择,如果插入异常, * 则会由DataSourceMonitor分析改异*常是由数据库问题造成,还是因为数据本身存在问题(如唯一性约束等), * 如果是数据库问题,则将该数据*源从重试列表中剔除 */public class RandomRetryableInserter{/** SqlMapClientTemplate管理器 */ SqlMapClientTemplateManager sqlMapClientTemplateManager; /** 最大重试次数 */ private static final int DEFAULT_MAX_RETRY_TIME = 5; /** 数据源监控器,用于判断异常是否由数据源引起 */ private DataSourceMonitor dataSourceMonitor; /** * @param statementName iBatis中sql-map文件中的sqlId * @param parameterObject 被保存的对象 * @return * @throws DataAccessException */ public InsertResult insert(final String statementName, final Object parameterObject) throws DataAccessException { int retryTime = 0; String dsNo = null; Long id = null; List<String> dsList = sqlMapClientTemplateManager.getAvailableDsNos(); while (StringUtil.isBlank(dsNo) && (retryTime < maxRetryTime) && (dsList.size() > 0)) { // 获取随机数据库操作模板 int dsNum = new Random().nextInt(dsList.size()); dsNo = dsList.get(dsNum); try { SqlMapClientTemplate sqlMapClitentTemplate = sqlMapClientTemplateManager.getSqlMapClientTemplate(dsNo); // 取得的模板为空,则下次不再重试该数据源 if (null == sqlMapClitentTemplate) { if ((retryTime++ <= DEFAULT_MAX_RETRY_TIME) && (dsList.size() > 0)) { dsList.remove(dsNum); continue; } else {//如果重试次数超过最大次数或者已没有可用的数据源来重试,则抛出异常 } } id = (Long) sqlMapClitentTemplate.execute(new SqlMapClientCallback() { public Object doInSqlMapClient(SqlMapExecutor executor) throws SQLException { return executor.insert(statementName, parameterObject); } }); } catch (Exception e) { //执行sql过程中,如果抛出异常,则检查该异常是数据库异常还是数据异常(譬如唯一性约束),如果是数据库异常 //则说明该数据源不正常,需要从重试列表中移除 if (dataSourceMonitor.judgeRetryableByException(dsNo, e)) { dsList.remove(dsNum); if ((retryTime++ <= DEFAULT_MAX_RETRY_TIME) && (dsList.size() > 0)) { //继续重试 } } else { throw new RuntimeException(e.getCause()); } } } //返回 }}?
?
首先看一下之前用到的judgeRetryableByException方法,该方法用于将不可用的数据源从缓存中剔除:
系统维护了一份mysql常见的错误码列表(如果DB是oracle,则采用oracle的错误码),根据传入的异常码判断是不是包含在列表中,如果是,则给该库的异常次数累加1,当异常次数达到最大次数后,则视该数据源为不可用,将该数据源从缓存的可用列表中清除,并移入待恢复的列表中。
?
然后分析一下数据源恢复方法:系统开启一个定时恢复任务,循环遍历待恢复的数据源列表,对于当前数据源,如果能够获取到connection,则表示数据源已经正常,则重新将该数据源加入到可用列表中
?