Kinect开发学习笔记之(七)骨骼数据的提取
Kinect开发学习笔记之(七)骨骼数据的提取
zouxy09@qq.com
http://blog.csdn.net/zouxy09
我的Kinect开发平台是:
Win7x86 + VS2010 + Kinect for Windows SDK v1.6 + OpenCV2.3.0
开发环境的搭建见上一文:
http://blog.csdn.net/zouxy09/article/details/8146055
本学习笔记以下面的方式组织:编程前期分析、代码与注释和重要代码解析三部分。
要实现目标:通过微软的SDK提取骨骼数据并用OpenCV显示
一、编程前期分析
Kinect产生的深度数据作用有限,要利用Kinect创建真正意义上交互,还需要除了深度数据之外的其他数据。这就是骨骼追踪技术的初衷,也是Kinect最神奇,最有作为的地方。骨骼追踪技术通过处理深度数据来建立人体各个关节的坐标,骨骼追踪能够确定人体的各个部分,如那部分是手,头部,以及身体,还能确定他们所在的位置。
1.1、骨架空间
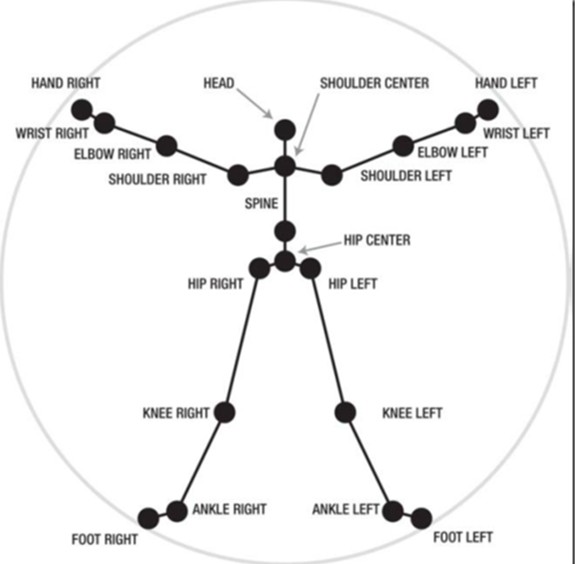
先看看啥叫骨架?应该地球人都知道吧。呵呵。在Kinect里面,是通过20个关节点来表示一个骨架的,具体由下图可以看到。当你走进Kinect的视野范围的时候,Kinect就可以把你的20个关节点的位置找到(当然你得站着),位置通过(x, y, z)坐标来表示。这样,你在Kinect前面做很多复杂的动作的时候,因为人的动作和这些关节点的位置的变化关系还是很大的,那么电脑拿到这些数据后,对于理解你做什么动作就很有帮助了。
玩家的各关节点位置用(x, y, z)坐标表示。与深度图像空间坐标不同的是,这些坐标单位是米。坐标轴x,y, z是深度感应器实体的空间x, y, z坐标轴。这个坐标系是右手螺旋的,Kinect感应器处于原点上,z坐标轴则与Kinect感应的朝向一致。y轴正半轴向上延伸,x轴正半轴(从Kinect感应器的视角来看)向左延伸,如下图所示。为了方便讨论,我们称这些坐标的表述为骨架空间(坐标)。
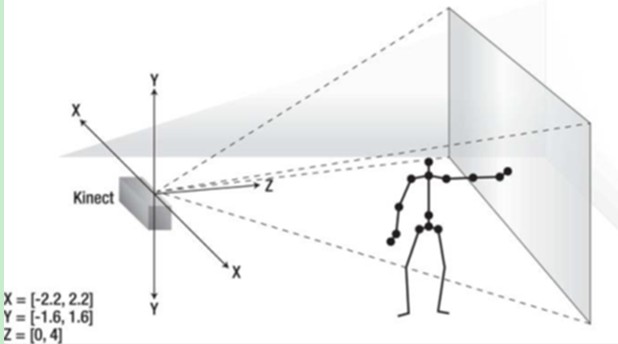
Kinect放置的位置会影响生成的图像。例如,Kinect可能被放置在非水平的表面上或者有可能在垂直方向上进行了旋转调整来优化视野范围。在这种情况下,y轴就往往不是相对地面垂直的,或者不与重力方向平行。最终得到的图像中,尽管人笔直地站立,在图像中也会显示出事倾斜的。
1.2、骨骼跟踪
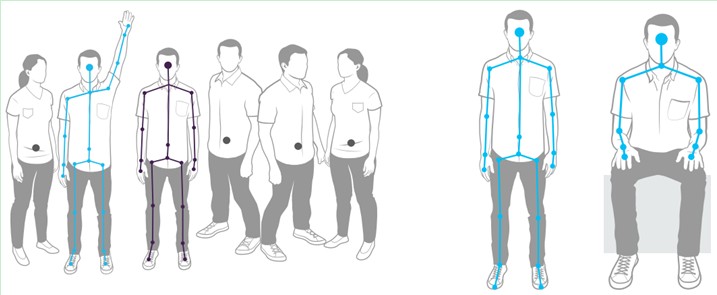
Kinect最多可以跟踪两个骨骼,可以最多检测六个人。站立模式可以跟踪20个关节点,坐着的模式的话,可以跟踪10个关节点。
NUI骨骼跟踪分主动和被动两种模式,提供最多两副完整的骨骼跟踪数据。主动模式下需要调用相关帧读取函数获得用户骨骼数据,而被动模式下还支持额外最多四人的骨骼跟踪,但是在该模式下仅包含了用户的位置信息,不包括详细的骨骼数据。也就是说,假如Kinect面前站着六个人,Kinect能告诉你这六个人具体站在什么位置,但只能提供其中两个人的关节点的数据(这两个人属于主动模式),也就是他们的手啊,头啊等等的位置都能告诉你,而其他的人,Kinect只能提供位置信息,也就是你站在哪,Kinect告诉你,但是你的手啊,头啊等具体在什么位置,它就没法告诉你了(这四个人属于被动模式)。
对于所有获取的骨骼数据,其至少包含以下信息:
1)、相关骨骼的跟踪状态,被动模式时仅包括位置数据(用户所在位置),主动模式包括完整的骨骼数据(用户20个关节点的空间位置信息)。
2)、唯一的骨骼跟踪ID,用于分配给视野中的每个用户(和之前说的深度数据中的ID是一个东西,用以区分现在这个骨骼数据是哪个用户的)。
3)、用户质心位置,该值仅在被动模式下可用(就是标示用户所在位置的)。
1.3、关于编程处理过程
在上篇文章中,我们讨论了如何获取像素点的深度值以及如何根据深度值产生影像。
彩色图像数据,深度数据分别来自ColorImageSteam和DepthImageStream,同样地,骨骼数据来自SkeletonStream。要使用骨架数据,应用程序必须在初始化NUI的时候声明,并且要启用骨架追踪。访问骨骼数据和访问彩色图像数据、深度数据一样,也有事件模式和查询模式两种方式。在本例中我们采用基于事件的方式,因为这种方式简单,代码量少,并且是一种很普通基本的方法。当SkeletonStream中有新的骨骼数据产生时就会触发该事件。
我们初始化并打开骨骼跟踪后,就可以从SkeletonStream中拿骨骼数据了。SkeletonStream产生的每一帧数据skeletonFrame都是一个骨骼对象集合。包含了一个骨架数据结构的数组,其中每一个元素代表着一个被骨架追踪系统所识别的一个骨架信息。每一个骨架信息包含有描述骨骼位置以及骨骼关节的数据。每一个关节有一个唯一标示符如头(head)、肩(shoulder)、肘(dlbow)等信息和对应的三维坐标数据。
Kinect能够追踪到的骨骼数量是一个常量。这使得我们在整个应用程序中能够一次性的为数组分配内存。循环遍历skeletonFrame,每一次处理一个骨骼。那么跟踪的骨骼也有跟得好与不好之分吧,你的姿势、是否有阻挡等等情况,都会使得跟踪不那边好。所以在处理之前需要判断一下是否是一个追踪好的骨骼,可以使用Skeleton对象的TrackingState属性来判断,只有骨骼追踪引擎追踪到的骨骼我们才进行处理,忽略哪些不是游戏者的骨骼信息即过滤掉那些TrackingState不等于SkeletonTrackingState.Tracked的骨骼数据。
Kinect能够探测到6个游戏者,但是同时只能够追踪到2个游戏者的骨骼关节位置信息。处理骨骼数据相对简单,首先,我们根据Kinect追踪到的游戏者的编号,用不同的颜色把游戏者的骨架画出来。
涉及的东西还是比较多的,但是代码思路还是比较清晰的,我们可以看代码,再看看第三部分的解析就会比较好理解了。
二、代码与注释
好了,感觉把这些说完,代码里面的东西就很容易读懂了。所以也没必要赘述了。但是还需要提到的几点是:
平滑化:
NuiTransformSmooth(&skeletonFrame,NULL);
在骨骼跟踪过程中,有些情况会导致骨骼运动呈现出跳跃式的变化。例如游戏者的动作不够连贯,Kinect硬件的性能等等。骨骼关节点的相对位置可能在帧与帧之间变动很大,这回对应用程序产生一些负面的影响。例如会影响用户体验和给控制造成意外等。
而这个函数就是解决这个问题的,它对骨骼数据进行平滑,通过将骨骼关节点的坐标标准化来减少帧与帧之间的关节点位置差异。
HRESULT NuiTransformSmooth(
NUI_SKELETON_FRAME *pSkeletonFrame,
const NUI_TRANSFORM_SMOOTH_PARAMETERS *pSmoothingParams
)
这个函数可以传入一个NUI_TRANSFORM_SMOOTH_PARAMETERS类型的参数:
typedef struct_NUI_TRANSFORM_SMOOTH_PARAMETERS {
FLOAT fSmoothing;
FLOAT fCorrection;
FLOAT fPrediction;
FLOAT fJitterRadius;
FLOAT fMaxDeviationRadius;
} NUI_TRANSFORM_SMOOTH_PARAMETERS;
NUI_TRANSFORM_SMOOTH_PARAMETERS这个结构定义了一些属性:
fSmoothing:平滑值(Smoothing)属性,设置处理骨骼数据帧时的平滑量,接受一个0-1的浮点值,值越大,平滑的越多。0表示不进行平滑
fCorrection:修正值(Correction)属性,接受一个从0-1的浮点型。值越小,修正越多。
fJitterRadius:抖动半径(JitterRadius)属性,设置修正的半径,如果关节点“抖动”超过了设置的这个半径,将会被纠正到这个半径之内。该属性为浮点型,单位为米。
fMaxDeviationRadius:最大偏离半径(MaxDeviationRadius)属性,用来和抖动半径一起来设置抖动半径的最大边界。任何超过这一半径的点都不会认为是抖动产生的,而被认定为是一个新的点。该属性为浮点型,单位为米。
fPrediction:预测帧大小(Prediction)属性,返回用来进行平滑需要的骨骼帧的数目。
空间坐标转换:
NuiTransformSkeletonToDepthImage(pSkel->SkeletonPositions[i], &fx, &fy );
由于深度图像数据和彩色图像数据来自于不同的摄像头,而这两个摄像头所在的位置不一样,而且视场角等也不也一样,所以产生的图像也会有差别(就好像你两个眼睛看到的东西都不一样,这样大脑才能通过他们合成三维场景理解),也就是说这两幅图像上的像素点并不严格一一对应。例如深度图像中,你在图像的位置可能是(x1,y1),但在彩色图像中,你在图像的位置是(x2,y2),而两个坐标一般都是不相等的。另外,骨骼数据的坐标又和深度图像和彩色图像的不一样。所以就存在了彩色坐标空间、深度坐标空间、骨骼坐标空间和你的UI坐标空间四个不同的坐标空间了。那么他们各个空间之前就需要交互,例如我在骨骼空间找到这个人在(x1,y1)坐标上,那么对应的深度图像,这个人在什么坐标呢?另外,我们需要把骨骼关节点的位置等画在我们的UI窗口上,那么它们的对应关系又是什么呢?
微软SDK提供了一系列方法来帮助我们进行这几个空间坐标系的转换。例如:
voidNuiTransformSkeletonToDepthImage(
Vector4 vPoint, //骨骼空间中某点坐标
FLOAT *pfDepthX, //对应的深度空间中的坐标
FLOAT *pfDepthY
)//将骨骼坐标转换到深度图像坐标上去。
HRESULTNuiImageGetColorPixelCoordinatesFromDepthPixel(
NUI_IMAGE_RESOLUTION eColorResolution,
const NUI_IMAGE_VIEW_AREA *pcViewArea,
LONG lDepthX,
LONG lDepthY,
USHORT usDepthValue,
LONG *plColorX,
LONG *plColorY
)//获取在深度图中具体坐标位置的像素在相应彩色空间中的像素的坐标。
Vector4NuiTransformDepthImageToSkeleton(
LONG lDepthX,
LONG lDepthY,
USHORT usDepthValue
)//传入深度图像坐标,返回骨骼空间坐标
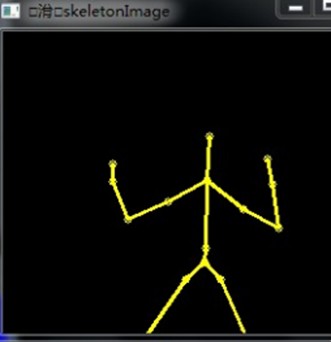
至此,目标完成,效果如下: