ubutun下eclipse调试hadoop的WordCount示例
1.先去hadoop官网下载hadoop的源码?http://svn.apache.org/repos/asf/hadoop/common/trunk
2.下载maven3,当前hadoop的最新版必须使用maven3编译3.到hadoop下载源码目录执行mvn clean install;mvn eclipse:eclipse;4.将源码导入eclipse;5.在eclipse设置执行的WordCount.java的jvm启动参数,最少需要两个,输入目录和输出目录??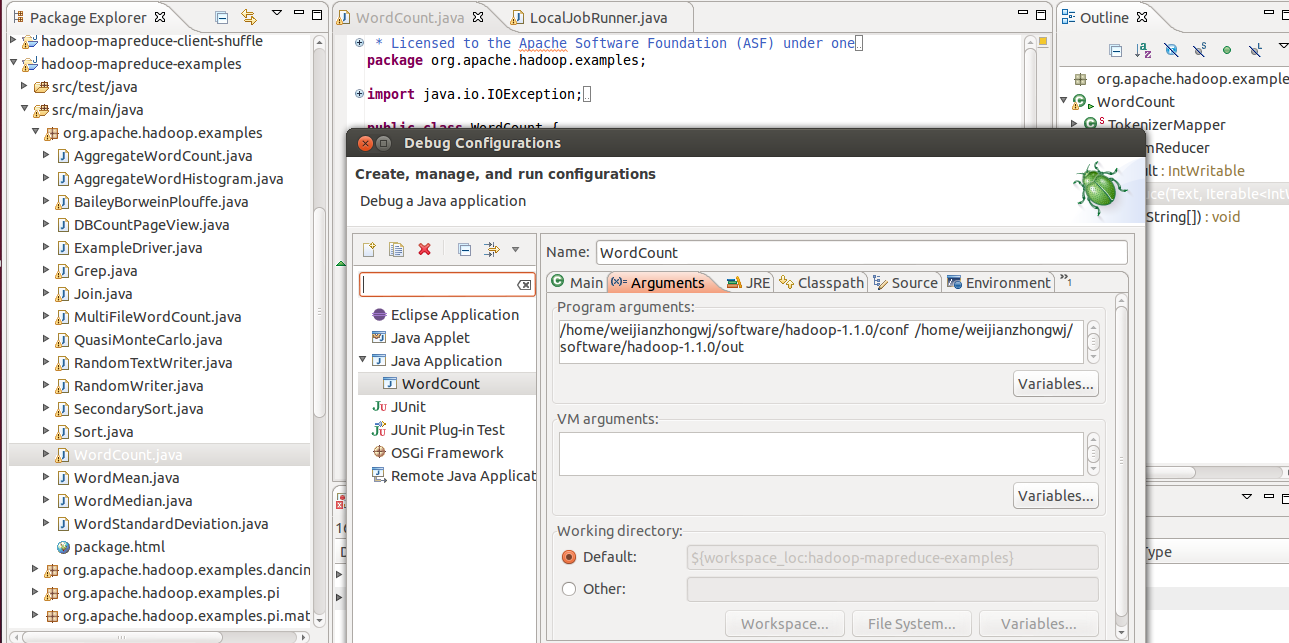
6.然后就可以设置断点进行调试了,我们在处理mapreduce的主干流程上设置断点
??org.apache.hadoop.mapred.LocalJobRunner这个类的run方法上
? 我们看到在我们设置的输入输出目录,然后使用默认的hadoop单机配置下,mapTask有16个,reduceTask有1个
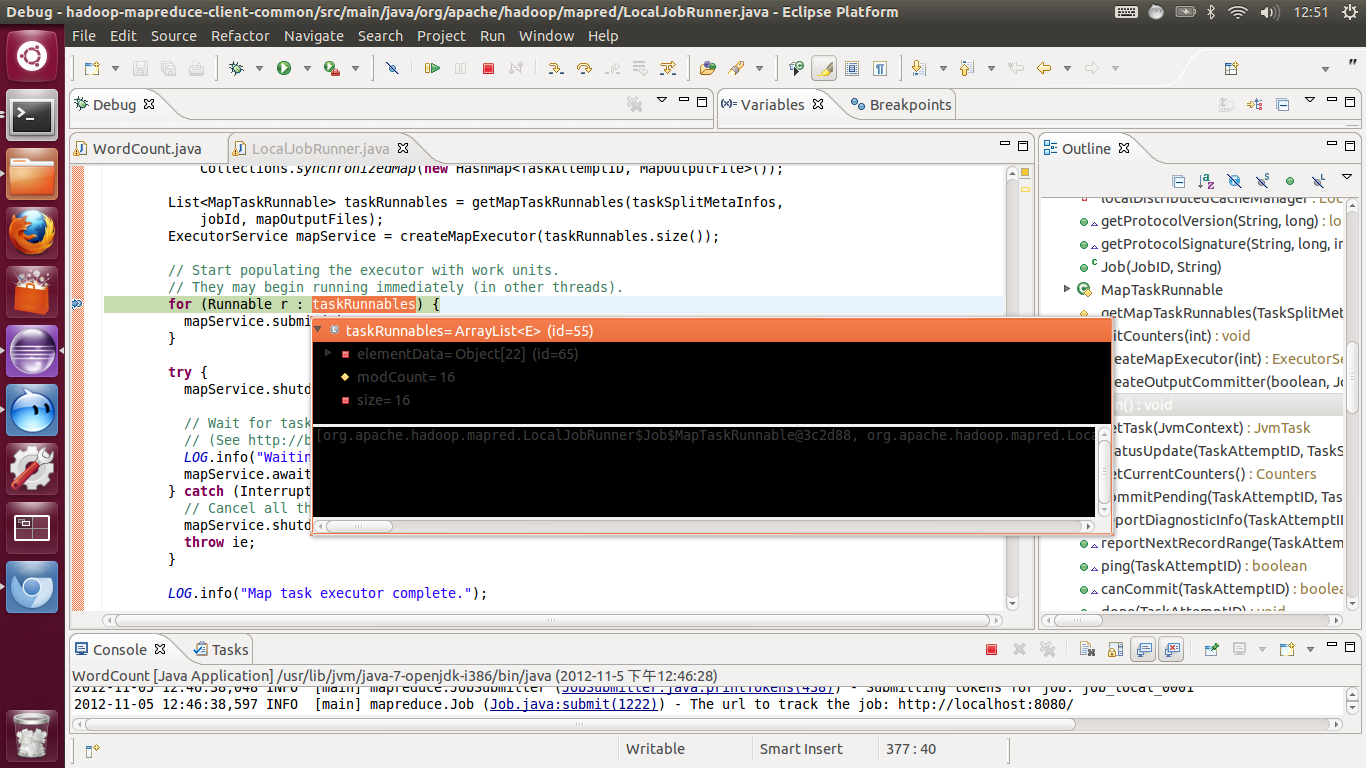
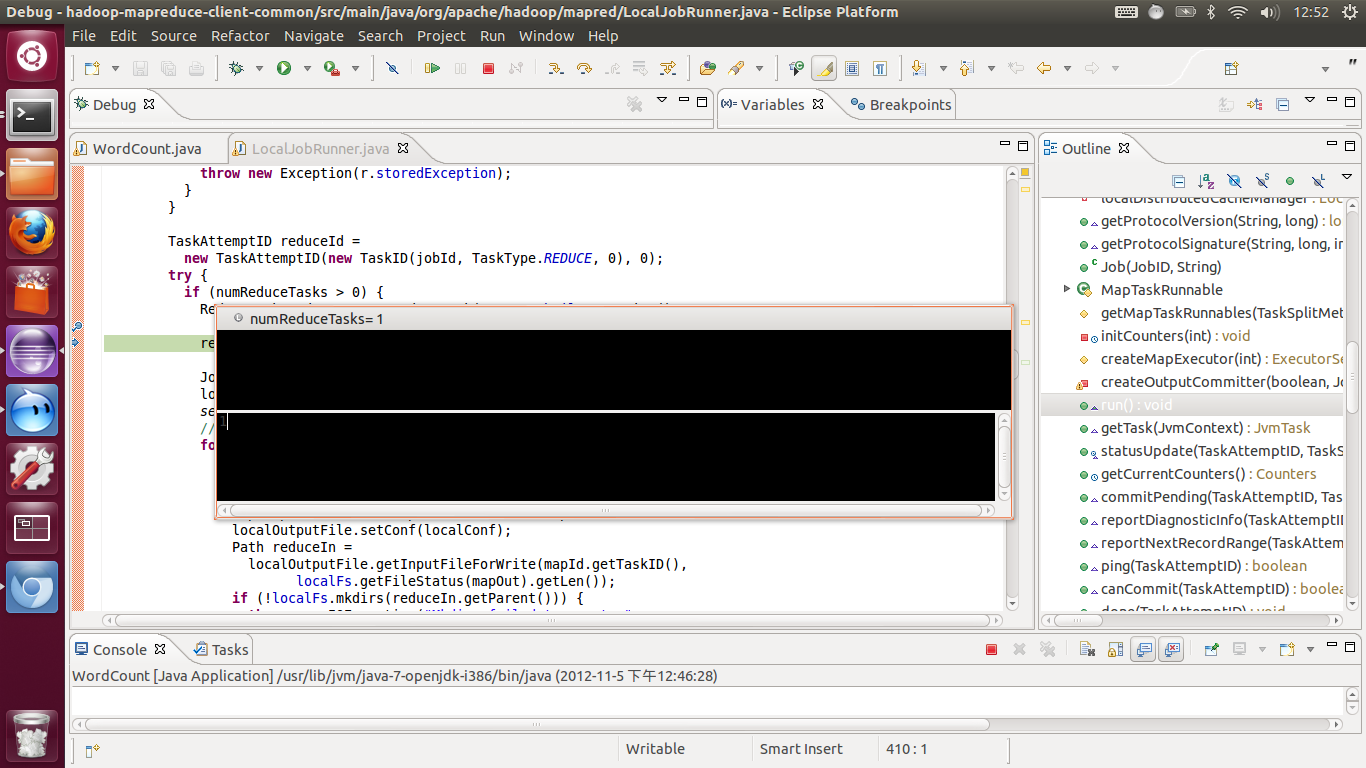
我们先看看我们的输入目录,刚好是16个文件,说明每个输入文件默认启动一个mapTask
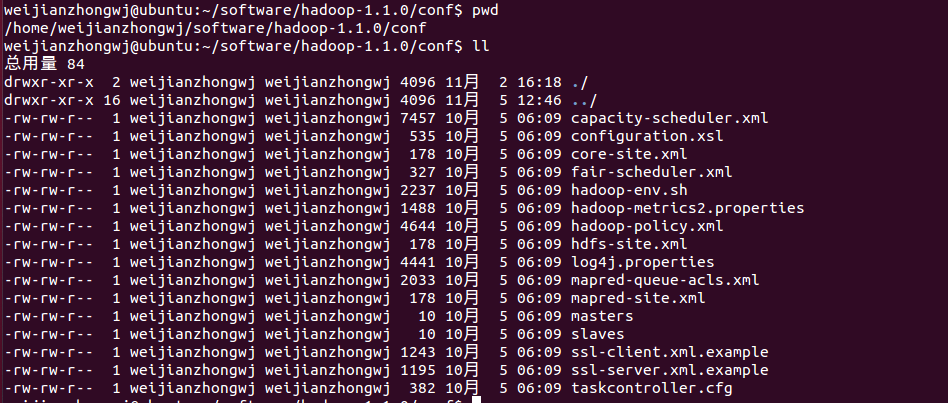
?
而reduce怎么是一个,怎么处理16个mapTask的输出呢
在org.apache.hadoop.mapred.ReduceTask这个reduce处理中run方法中会对所有的map输出做一个merge,然后作为reduceTask的输入
?