使用 JavaScript 拦截和跟踪浏览器中的 HTTP 请求
HTTP 请求的拦截技术可以广泛地应用在反向代理、拦截 Ajax 通信、网页的在线翻译、网站改版重构等方面。而拦截根据位置可以分为服务器端和客户端两大类,客户端拦截借助 JavaScript 脚本技术可以方便地和浏览器的解释器及用户的操作进行交互,能够实现一些服务器端拦截不容易实现的功能。本文将重点介绍通过 JavaScript 脚本在客户端对页面内容进行拦截修改的一些原理和技术。
HTTP 请求的拦截功能的应用随着互联网应用及 B/S 架构的软件系统的风行,越来越多的基于浏览器的应用得以开发和部署。对已经上线的应用系统进行拦截和跟踪可以方便、快捷地实现很多功能。例如,
?? 1. IBM 的 Tivoli Access Manager 单点登录(SSO,关于更多 TAM 的信息,请参见本文后附的资源列表)就是基于逆向代理服务器的原理实现的,逆向代理服务器的实现必须要对既有页面中的一些 URL 进行拦截和改写;
?? 2. 现今一些有趣的匿名代理服务器也是根据逆向代理服务器的原理实现的(如 http://www.youhide.com/),这类网站也有 URL 改写的需求;
?? 3. 另外,IBM 提供的在线翻译网页的服务中,为了能够让被翻译页面的链接所指向的页面在用户交互时继续得到翻译,我们同样需要使用 URL 的拦截和改写功能。
不仅仅是 URL 改写,通过拦截和跟踪技术可以在极小修改或者使用反向代理不修改原网页的前提下为基于 BS 的 Web 应用提供更复杂的页面改写,脚本改写等功能。
如图 1 所示,传统的 Web 访问模型通过浏览器向 HTTP 服务器获取 Web 数据,浏览器将获取的数据进行解释渲染,得到用户的客户端界面。
图 1. 传统 Web 访问模型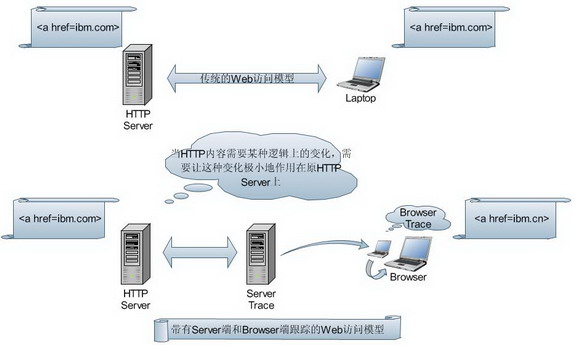
而在带有服务器端和浏览器端跟踪和拦截的访问模型中,传统的访问方式发生了变化。服务器端和浏览器端的跟踪和拦截将页面中的拦截对象,在适当的拦截时机进行了拦截变化,导致用户面前的浏览器的解释渲染结果和 HTTP 服务器上的内容存在了逻辑上的差异,而这种差异恰巧是 HTTP Server 所需要的结果,而不方便将差异部署在 HTTP Server 上。 Server trace 可以作为反向代理服务器的一项逻辑功能存在,Browser trace 是通过脚本完成在客户端拦截和跟踪行为。
拦截根据位置可以分为服务器端和客户端两大类,客户端拦截借助 JavaScript 脚本技术可以方便地和浏览器的解释器和用户的操作进行交互,能够实现一些服务器端拦截不容易实现的功能。如果将服务器端和客户端拦截融合在一起,可以很好地处理拦截和跟踪问题。
表 1. 服务器端拦截和客户端拦截的功能比较图 2 是个简单的 HTML 文本分析状态图,不支持 HTML 的 & 字符串拼接功能。可以反复调用这个模块用来从 HTML 文档中提取字符块生成相应的节点,然后可以利用 JavaScript 的正则表达时提取节点的属性。
通过 HTML 文本分析状态图可以得到 HTML 解析的代码,然后得到一个根为 root 的节点。后面对树进行进一步的处理,就可以实现很多拦截功能。比如 function 覆盖。前面讲到的用户自定义函数覆盖会受到代码插入点复杂的影响。如果在这种方法的拦截下,就可以实现分析出 <script> 节点的内容中含有特定的 function 定义,进而替换或者在其后插入新的函数定义,不会造成插入点复杂的结果。结论
通过上面的介绍,可以看出发挥 JavaScript 的优势,我们能够很好的控制页面的加载过程,在不需要二进制浏览器插件的情况下,仅仅通过脚本对 Web 内面的逻辑拦截是可行的。这种方法在反向代理、网站的改版重构、以及不方便对原有内容进行直接改动的场合是十分有益的。