openCl-work-item的并行的理解
最近在看OpenCL的程序,对于work-item的运行机制不是很理解。于是,自己用几个小程序直观的看了一下,主要是在用OpenMP的测试思想,输出work-item及其处理的数据结果。个人感觉这个对于我理解其运行机制很有帮助,以下是程序:
主机端程序:main.cpp
/* 项目:openCL的矩阵相乘 作者:刘荣 时间:2012.11.20*/#include <iostream>#include<time.h>#include <string> #include<math.h>#include <vector>#include <CL/cl.h>#include <fstream>using namespace std;//kernel函数std::stringconvertToString(const char *filename)//将kernel源码,即自己写的并行化的函数,转化成字符串{ size_t size; char* str; std::string s; std::fstream f(filename, (std::fstream::in | std::fstream::binary)); if(f.is_open()) { size_t fileSize; f.seekg(0, std::fstream::end); size = fileSize = (size_t)f.tellg(); f.seekg(0, std::fstream::beg); str = new char[size+1]; if(!str) { f.close(); std::cout << "Memory allocation failed"; return NULL; } f.read(str, fileSize); f.close(); str[size] = '\0'; s = str; delete[] str; return s; } else { std::cout << "\nFile containg the kernel code(\".cl\") not found. Please copy the required file in the folder containg the executable.\n"; exit(1); } return NULL;}int main(){double start,end,time1,time2;//查询平台cl_int ciErrNum;cl_platform_id platform;ciErrNum = clGetPlatformIDs(1, &platform, NULL);if(ciErrNum != CL_SUCCESS){cout<<"获取设备失败"<<endl;return 0;}//获取设备信息cl_device_id device;cl_int status; cl_uint maxDims; cl_event events[3]; size_t globalThreads[1]; size_t localThreads[1]; size_t maxWorkGroupSize; size_t maxWorkItemSizes[3]; //////////////////////////////////////////////////////////////////// // STEP 7 Analyzing proper workgroup size for the kernel // by querying device information // 7.1 Device Info CL_DEVICE_MAX_WORK_GROUP_SIZE // 7.2 Device Info CL_DEVICE_MAX_WORK_ITEM_DIMENSIONS // 7.3 Device Info CL_DEVICE_MAX_WORK_ITEM_SIZES //////////////////////////////////////////////////////////////////// /** * Query device capabilities. Maximum * work item dimensions and the maximmum * work item sizes */ ciErrNum = clGetDeviceIDs(platform, CL_DEVICE_TYPE_ALL, 1, &device, NULL); status = clGetDeviceInfo( device, CL_DEVICE_MAX_WORK_GROUP_SIZE, sizeof(size_t), (void*)&maxWorkGroupSize, NULL); if(status != CL_SUCCESS) { std::cout << "Error: Getting Device Info. (clGetDeviceInfo)\n"; return 0; } status = clGetDeviceInfo( device, CL_DEVICE_MAX_WORK_ITEM_DIMENSIONS, sizeof(cl_uint), (void*)&maxDims, NULL); if(status != CL_SUCCESS) { std::cout << "Error: Getting Device Info. (clGetDeviceInfo)\n"; return 0; } status = clGetDeviceInfo( device, CL_DEVICE_MAX_WORK_ITEM_SIZES, sizeof(size_t)*maxDims, (void*)maxWorkItemSizes, NULL); if(status != CL_SUCCESS) { std::cout << "Error: Getting Device Info. (clGetDeviceInfo)\n"; return 0; }cout<<"maxWorkItemSizes"<<maxWorkItemSizes<<endl;cout<<"maxDims"<<maxDims<<endl;cout<<"maxWorkGroupSize"<<(int)maxWorkGroupSize<<endl;//创建上下文cl_context_properties cps[3] = {CL_CONTEXT_PLATFORM, (cl_context_properties)platform, 0};cl_context ctx = clCreateContext(cps, 1, &device, NULL, NULL, &ciErrNum);if(ciErrNum != CL_SUCCESS){cout<<"创建上下文失败"<<endl;return 0;}cl_command_queue myqueue = clCreateCommandQueue(ctx,device,0,&ciErrNum);if(ciErrNum != CL_SUCCESS){cout<<"命令队列失败"<<endl;return 0;}//声明buffer,传输数据float *C = NULL; // 输出数组float *B = NULL; // 输出数组int c=10;size_t datasize = sizeof(float)*c;// 分配内存空间C = (float*)malloc(datasize);B = (float*)malloc(datasize);// 初始化输入数组cl_mem bufferC = clCreateBuffer(ctx,CL_MEM_WRITE_ONLY,c*sizeof(float),NULL,&ciErrNum);cl_mem bufferB = clCreateBuffer(ctx,CL_MEM_WRITE_ONLY,c*sizeof(float),NULL,&ciErrNum);//运行时kernel编译const char * filename = "simpleMultiply.cl"; std::string sourceStr = convertToString(filename); const char * source = sourceStr.c_str(); size_t sourceSize[] = { strlen(source) };//直接将CL文件读到记忆体 cl_program myprog = clCreateProgramWithSource( ctx, 1, &source, sourceSize, &ciErrNum);//cl_program myprog = clCreateProgramWithSource(ctx,1,(const char**)&programSource,NULL,&ciErrNum);if(ciErrNum != 0){cout<<"createprogram failed"<<endl;}ciErrNum = clBuildProgram(myprog,0,NULL,NULL,NULL,NULL);if(ciErrNum != 0){cout<<"clBuildProgram failed"<<endl;}cl_kernel mykernel = clCreateKernel(myprog,"vecadd",&ciErrNum);if(ciErrNum != 0){cout<<"clCreateKernel failed"<<endl;}//运行程序clSetKernelArg(mykernel,0,sizeof(cl_mem),(void*)&bufferB);clSetKernelArg(mykernel,1,sizeof(cl_mem),(void*)&bufferC); size_t globalWorkSize[1];globalWorkSize[0] = c/2;////start = clock();ciErrNum = clEnqueueNDRangeKernel(myqueue,mykernel,1,NULL,globalWorkSize,NULL,0,NULL,&events[0]);if(ciErrNum != 0){cout<<"clEnqueueNDRangeKernel failed"<<endl;}//时间同步status = clWaitForEvents(1, &events[0]); if(status != CL_SUCCESS) { std::cout << "Error: Waiting for kernel run to finish. \ (clWaitForEvents0)\n"; return 0; } cout<<"o"<<endl; status = clReleaseEvent(events[0]);//将结果拷贝到主机端end = clock();time1=end-start;cout<<"shijian "<<time1<<endl;ciErrNum = clEnqueueReadBuffer(myqueue,bufferC,CL_TRUE,0,datasize,C,0,NULL,&events[1]);status = clWaitForEvents(1, &events[1]); if(status != CL_SUCCESS) { std::cout << "Error: Waiting for read buffer call to finish. \ (clWaitForEvents1)n"; return 0; } status = clReleaseEvent(events[1]); if(status != CL_SUCCESS) { std::cout << "Error: Release event object. \ (clReleaseEvent)\n"; return 0; }ciErrNum = clEnqueueReadBuffer(myqueue,bufferB,CL_TRUE,0,datasize,B,0,NULL,&events[2]);status = clWaitForEvents(1, &events[2]); if(status != CL_SUCCESS) { std::cout << "Error: Waiting for read buffer call to finish. \ (clWaitForEvents1)n"; return 0; } status = clReleaseEvent(events[2]); if(status != CL_SUCCESS) { std::cout << "Error: Release event object. \ (clReleaseEvent)\n"; return 0; }//for(int i=0; i<c/2; i++){ cout<<"work-item:"<<B[i]<<":";for(int j=0;j<2;j++){ cout<<C[i+j]<<" ";}cout<<endl;}return 0;}kernel函数 simpleMultiply.cl
// Enter your kernel in this window__kernel void vecadd(__global float* B,__global float* C) { int id = get_global_id(0); // barrier(CLK_LOCAL_MEM_FENCE); B[id] = id; for(int i =0;i<2;i++) { C[id*2+i] = i; } // barrier(CLK_LOCAL_MEM_FENCE); };
运行结果:
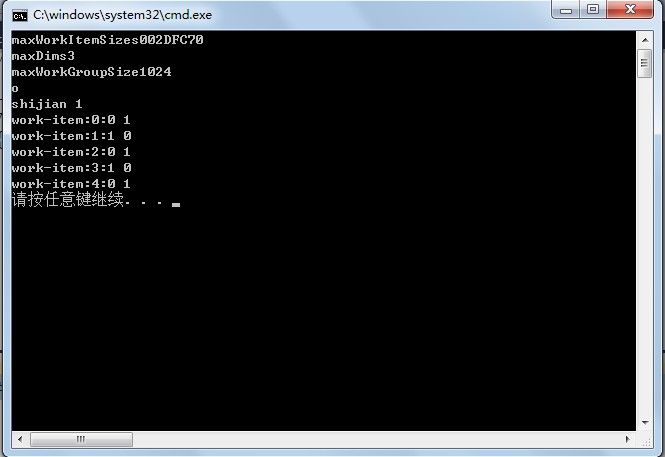
从上面的结果中,可以看出每个work-item独立运行,