【Struct(结构体)杂谈之五】以空间换时间,Struct(结构体)中的成员对齐之道(下)
Struct(结构体)中的成员对齐之道(下)
(作者:tcpipstack 出处:http://blog.csdn.net/tcpipstack , 欢迎转载,也请保留这段声明。谢谢!)
引言在上一篇【Struct(结构体)杂谈之四】以空间换时间,Struct(结构体)中的成员对齐之道(上) 中,我们了解到struct ALIGN2 和 struct ALIGN3的成员变量都是1个int型,1个char型及1个short型,可是它们所占的空间却1个是8字节,一个是12字节。
为什么会有这样的区别呢?通过上篇关于对齐的介绍,我们已经猜测这是因为编译器对其作了对齐的处理所致,但是编译器处理的细节具体是什么呢?
编译过程详解一般情况下,c程序的编译过程为
预处理编译成汇编代码汇编成目标代码链接
这一篇我们将使用gcc对上述几个细节进行仔细分析,了解其处理细节:源码如下:
我们可以绘出其内存分配图:
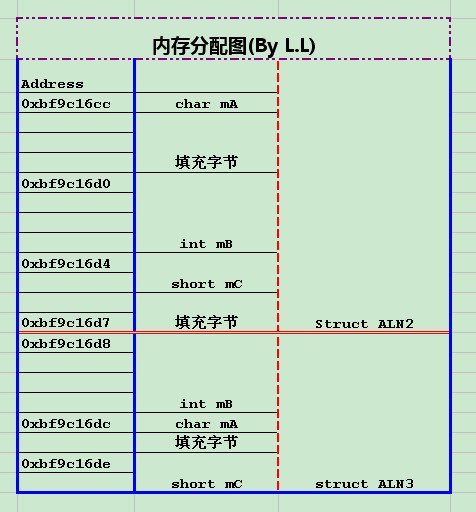
假如我们不对齐的后果上图是内存对齐的struct ALN2和struct ALN3的内存分配情况,假如我们不对齐呢?其内存分配如下所示:

很明显,int mB 和 short mC都不满足对齐要求。
对齐可以提高取数据的效率在IA32架构中,数据总线是32位,即一次可以存取4个字节的数据。
在对齐的情况下,struct ALN2的每个成员都可以在一个指令周期内完成;
而假设我们的struct ALN2没有对齐,那么对于struct ALN2中char mA,CPU可以一次取出4个字节获得低位的一个字节,同时需要将高位的3个字节保存在寄存器中,之后的int mB,CPU必须再取得低位的1个字节并通之前保存在寄存器中的数据结果组合在一起,每一个都需要好几条指令,是不是相当麻烦?
如何自定义对齐?那肯定有同学要问了,有没有办法让处理器按照自己的要求进行地址对齐呢?
---当然可以,我们可以通过预编译命令#pragma pack(n),n=1,2,4,8,16来改变这一系数,其中的n就是你要指定的“对齐系数”。
比如,我想让处理器按照1个字节的方式对齐,则代码如下:
可以看出,在我们要求的1字节对齐方式下,aln2和aln3的结果都是7,只占了4+2+1个字节,内存空间一个字节都利用到极致。
至此,关于内存对齐就到此告一段落了,你弄明白了吗?
(作者:tcpipstack 出处:http://blog.csdn.net/tcpipstack , 欢迎转载,也请保留这段声明。谢谢!)
我们可以绘出其内存分配图:

假如我们不对齐的后果上图是内存对齐的struct ALN2和struct ALN3的内存分配情况,假如我们不对齐呢?其内存分配如下所示:

很明显,int mB 和 short mC都不满足对齐要求。
对齐可以提高取数据的效率在IA32架构中,数据总线是32位,即一次可以存取4个字节的数据。
在对齐的情况下,struct ALN2的每个成员都可以在一个指令周期内完成;
而假设我们的struct ALN2没有对齐,那么对于struct ALN2中char mA,CPU可以一次取出4个字节获得低位的一个字节,同时需要将高位的3个字节保存在寄存器中,之后的int mB,CPU必须再取得低位的1个字节并通之前保存在寄存器中的数据结果组合在一起,每一个都需要好几条指令,是不是相当麻烦?
如何自定义对齐?那肯定有同学要问了,有没有办法让处理器按照自己的要求进行地址对齐呢?
---当然可以,我们可以通过预编译命令#pragma pack(n),n=1,2,4,8,16来改变这一系数,其中的n就是你要指定的“对齐系数”。
比如,我想让处理器按照1个字节的方式对齐,则代码如下:
可以看出,在我们要求的1字节对齐方式下,aln2和aln3的结果都是7,只占了4+2+1个字节,内存空间一个字节都利用到极致。
至此,关于内存对齐就到此告一段落了,你弄明白了吗?
(作者:tcpipstack 出处:http://blog.csdn.net/tcpipstack , 欢迎转载,也请保留这段声明。谢谢!)