Hbase的优化总结
Hbase的优化总结
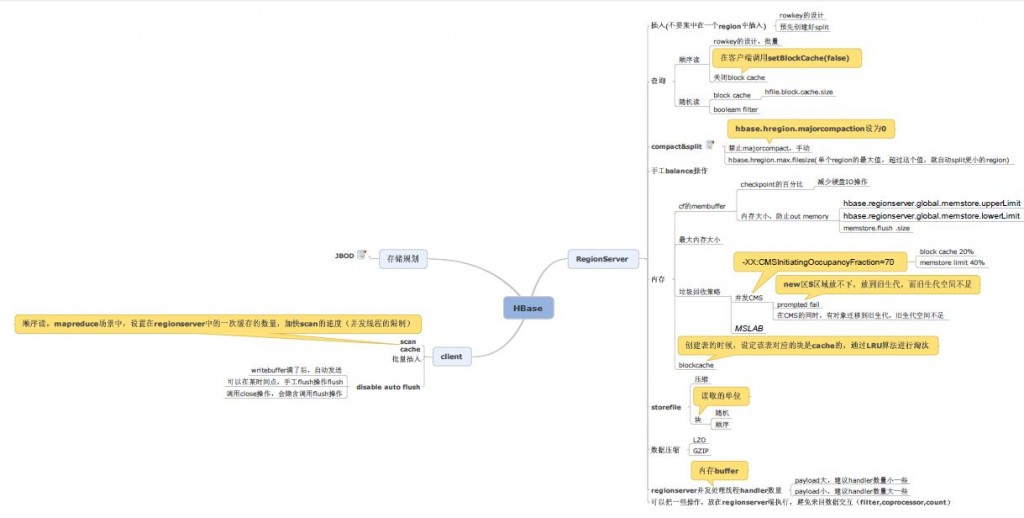
上面这张图不是一太清晰,我后面给个单独的连接
这里的HBase的优化主要从三个大的维度来进行分析
1、系统硬件
采用普通的PC Server即可,Master要求高一点(比如8 CPU,48G内存,SAS raid),Regionserver(如8CPU,24G内存,1T*12 SATA JBOD)
对于存储regionserver节点采用JBOD,master采用sas raid1+0
数据的存储在hdfs中本身考虑到了冗余,一般情况下replication设置为3,所以不用做raid;需要考虑的是每个节点的可用的存储空间的大小,所以这里用磁盘簇的方式。
网卡千兆的,做网卡bond,并且管理网段和请求网段分开,对于大的混合集群来说,可以设计多个vlan。
2、客户端client
a、 scan cache:顺序读的场景中,比如mapreduce做计算,可以设置在regionserver中的一次缓存的数量,可以加快scan的进度,
不过考虑到regionserver的内存限制,需要注意regionserver并发线程的控制。
b、在插入数据时,最好用批量插入操作,效率会更高一些。
c、auto flush最好disable掉
对于client来说,有一个writebuffer的缓冲,buffer满了之后,自动的发送数据到regionserver端
可以在某个时间点,手动调用flush的操作进行flush数据
调用close操作,会隐含调用flush操作
3、regionserver
a、对于插入操作,不要集中在一个region中插入,需要考虑rowkey的设计(rowkey如果是顺序设计的,这样会集中插入到一个region中),以及最好预先创建好split region
b、对于查询操作时,又分为两种情况,一种是顺序读,一种是随机读。
顺序读,最好rowkey是连续的设计的,这样可以从一个region中批量读数据;并且关闭block cache(客户端调用setBlockCache(false))。
随机读,打开block cache(设置cache合理大小,hfile.block.cache.size);采用booleam filter,提供随机查询的效率。
当然HFile块的大小设计很重要,随机读的情况下,可以设置小一点,顺序读的情况下,设计大一下。
c、对于compact&split操作,建议禁止major compact(hbase.hregion.majorcompaction设为0),该为手动方式,每天不忙的时候进行。
设置单个region的合理的大小(hbase.hregion.max.filesize),超过这个值,就自动进行split操作。
d、手动进行balancer操作
e、内存大小的相关考虑
1) 对于region column family 的buffer,设置合理的checkpoint百分比,减少硬盘IO的操作;对buffer memstore设计合理大小,防止内存溢出。
主要有这三个参数,hbase.regionserver.global.memstore.upperLimit,hbase.regionserver.global.memstore.lowerLimit,memstore.flush .size
2)regionserver JVM参数设置
设置最大合理内存大小
垃圾回收策略,并发CMS的设置,比如-XX:CMSInitiatingOccupancyFraction=70,memstore limit 40%,block cache 20%,
防止promted fail(new区S区域放不下,放到旧生代,而旧生代空间不足),防止CMS的同时 ,对象迁移到旧生代,而旧生代空间不足。
为了避免CMS带来的碎片,可以考虑采用MSLAB
3) block cache,创建表时,设置该表对应的块是cache的,通过LRU算法淘汰;不过块中的数据索引dataIndex是放在内存中的。
f、HFile的设置
1)可以压缩存储,减少磁盘和网络IO,有GZIP、LZO、Snappy,一般采用LZO或者Snappy。
2)对于HFile中块的大小设置,可以根据顺序读和随机读的比重,来考虑(顺序读,块设置大,随机读,块设置小一点)
g、regionserver并发处理线程handler的的数量(payload大,建议handler数量小一些,反之,建议handler数量大一些)
h、可以把一些操作,放在regionserver端执行,避免来回数据交互(filter,coprocessor,count)
相关参数设置参考
client
Scan Caching(默认是1条,设置成20条)
Scan Attribute Selection
Close ResultScanners
AutoFlush(默认是true,设置成false)
Bloom Filter
regionserver
内存
JVM(CMS GC,24G heap,-XX:CMSInitiatingOccupancyFraction=70)
hbase.regionserver.global.memstore.upperLimit(默认0.4)
hbase.regionserver.global.memstore.lowerLimit(默认0.3)
hbase.hregion.memstore.flush.size(64M,如果region的数量不多,可以设置的大一些,假如有1000个region*200M)
hbase.hregion.memstore.block.multiplier(默认是2)
hfile.block.cache.size(默认是0.2,场景中是读多写少,建议开大一些,0.4)
hbase.hregion.memstore.mslab.enabled
文件大小
hbase.hregion.max.filesize(默认256M,实际环境中为1G,每天手动split,compact)
hbase.hstore.blockingStoreFiles(默认7),通常情况下,一个storeFile大概在200M的样子,当进行major compact时,会合并成一个
线程设置
hbase.regionserver.handler.count(默认是10,设置成100,和内存大小有关系)