DataStage:DataStage8.5-分区方法(Partition)
1、自动(Auto)分区
自动分区是开发作业时最普遍的分区方式。DataStage将根据本身stage的类型和前一个stage所做的操作,决定一个最优的分区方案。一般情况下,对最初的输入数据一般采用循环分区(Round Robin)方法,而对于作业中除第一个Stage之外的其他Stage,一般就都采用Same分区了。
2、完全(Entire)分区
对于同一个stage的各个实例,在每个节点上都能访问到全部的输入数据,也就是说数据并未分区,只是复制了几份分发到各个节点上。
这有什么用呢?可能有时候,每个节点都需要访问全部的输入数据,但是同时也想利用一下并行引擎,此时完全分区就是一个很好的解决方案。
最有可能用到这种分区方法的就是Lookup stage。当Lookup的主输入被分区后,每个节点上都只有部分数据。但Lookup输入不能被分区,否则主输入上的数据就有可能在某个Lookup链接上找不到相应的数据,因此所有的Lookup输入都应该有完整的Lookup数据。这就是完全分区发挥作用的地方了。
3、哈希(Hash)分区
对输入数据中每条记录的一个或者多个字段的值进行函数计算,得到一个哈希值,哈希值相同的记录被划分到同一个分区。用来计算哈希值的字段,称做哈希分区键。
哈希分区所产生的各个分区中,数据是否均匀,取决于所选取的分区键。比如在人口数据表中,如果选用邮编作为分区键,那么可能少数分区被分配了大量的数据,其他分区的数据则较少。这很容易产生瓶颈。
所以使用哈希分区时最关键的是分区键的选择。一般都不会选择只有少数几个值的字段作为分区键,比如性别,是否,对错等等,而应该选择数据中能产生大量分区的字段。这跟实际的数据紧密相关。
在进行分组和去重操作时,一般需要选择哈希分区,这可以保证相近的数据能分配到同一个分区。
4、模数(Modulus)分区
取输入数据中的一个字段作为模,然后除以总的节点数,得到的余数即为分区号,再根据分区号将该行记录送入相应的分区中。
比如输入数据中有一整型字段,其中有四个值如下:44913,22672,90745,4703,总的逻辑节点为四个,44913除4余1,该行记录将被分配到partition 1中,22672除4余0,该行记录将被分配到partition 0中,90745除4余1,该记录也被分配到partition 1中,4703除4余3,该记录就被分配到partition 3中。
由此可见,模数分区方法所产生的分区也是非常不均匀的,有些分区甚至可能空缺,比如例子中的partition 2,有些分区则可能有很多数据,比如partition 1。再有,模数分区所选取的模数字段,最好是整型,否则取模时弄出无数的小数,反倒有可能降低性能。
同哈希分区相比,模数分区与之有些类似,但是只支持一个字段作为关键字,关键字的选取也有较高求,同时算法也变得相对简单。
5、随机(Random)分区
DataStage将输入数据随机地分配到所有节点上。
与循环分区类似,随机方法所产生的分区,各个节点上处理的数据也都大致相等。但与循环分区相比,随机分区需要的系统资源开销要大,因为这种方法在分区时,要为每条记录都生成一个随机值。相对循环分区来讲,开销自然要大。
6、Same分区
它什么也不做,仅仅将在前一个stage中已经分区过的数据,依然保留在同样的节点上,并不重新进行分区。因此,Same分区是最快的分区方法。
一般情况下,Same分区用于在各个stage之间传递数据。典型的比如Copy stage。
7、循环(Round Robin)分区
将数据按一定的方式进行排序,并依照这种排序方式逐条记录提取,逐个放到分区里。比如有10000条数据,把这10000条数据分成3个分区,如果选择ROUND分区方法,DS就会把第一条数据放到第一个分区了,第二条记录放到第二个分区,第三条记录放到第三个分区,然后循环回来,第四条记录放到第一个分区,第五条记录放到第二个分区,依此类推。
8、DB2分区
DB2分区并不是指对DB2表的分区,而是指对输入数据进行分区,只不过这种分区方法与DB2对表的分区方法是一样的,选用这种分区方法的同时,必须也指定相应的DB2表。
9、范围(Range)分区
范围(Range)分区范围分区与前面所讲的几种分区方法相比,有两个主要特点,一是需要为它指定分区键,另一个是它会尽量平均分配数据到各个节点上。指定分区键的操作与模数(Modulus)分区和哈希(Hash)分区相似,但后两者不能保证分区后数据的均匀性;随机分区(Random)和循环分区能保证数据的均匀性,但是这两者不能指定分区键。所以范围分区兼有两种分区方法的特点。
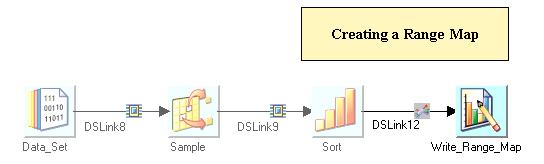
范围分区可以指定多个分区键,它的具体操作方法是按分区键所在的范围将数据尽量平均分配到各个节点上。但要使用这种分区方法,需要先使用一个名为生成范围对照表(Write Range Map)的stage生成一个范围对照表(Range Map),然后stage将依照这个对照表中的内容对数据进行范围分区。
这个生成范围对照表的stage原理非常简单,它使用Sample stage对源数据进行取样,以较小的数据量生成一个分区边界范围表,供需要使用范围分区的Stage使用。它只有一个输入链接。如下所示: