数据挖掘:Top 10 Algorithms in Data Mining(七)AdaBoost
Adaboost 是boosting算法的变形,全称为adaptive boosting(自适应增强)。该方法主要是通过多个弱分类器的集合来使得分类误差达到足够小。理论上通过adaboost方法可以使得分类误差为0。但我们知道通常情况下训练分类器误差为0时会过拟合。
关于boosting算法参考《Boosting Foundations and Algorithms》以及wiki :http://en.wikipedia.org/wiki/Boosting_(machine_learning)
Adaboost中弱分类器指准确率仅比随机猜测略高的分类器算法; 识别准确率很高并能在多项式时间内完成的学习算法称为强学习器算法。在adaboost中每个样本有一个权值,用于表示其被某个分类器选入训练集的概率。如果一个样本已经被准确的分类,那么在下一轮构造新训练集时其被选中的概率将降低。相反,未被正确分类的则权重增加。这样那些难于分类的样本将得到更多的重视。
X^i,yi分别表示原始样本集D与他们的标记。Wk(i)表示第k次迭代全体样本的权重分布。n为样本总数。Adaboost 伪代码:
- Begin initialize D={x^1,y1,……,x^n,yn},kmax, W1(i)=1/n,i=1,……,n
- k=0
- Do k=k+1
- 用Wk(i)采样训练集用以训练弱分类器Ck
- Ek=使用4中样本集测量的Ck误差
- Ak=(1/2)ln[(1-Ek)/Ek]
- Wk+1(i)=Wk(i)/Zk *
- until k=kmax
- Return Ck 和 ak k=1,……,kmax(带权分类器的总体)
- End
Zk为归一化操作。最后的分类器可以用所有子分类器的加权和来表示
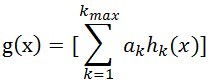
hk(x)表示第k轮分类器对x的分类结果。
前面我们说到原理上当k很大时很可能发生过拟合,但很多仿真实验表明即使K很大时也很少发生过拟合现象。