如何解析复杂的文本
(study "Test"
(rootasset "Test"
(asset "Test"
(asset "A"
(data "inputs"
("CFID" "text" "评估编号")
("CODE" "text" "代码")
("SEQNUM" "text" "序号")))
(asset "B"))))
有以上这样的一个文本,通过一个第三方的软件解析的结果为下图: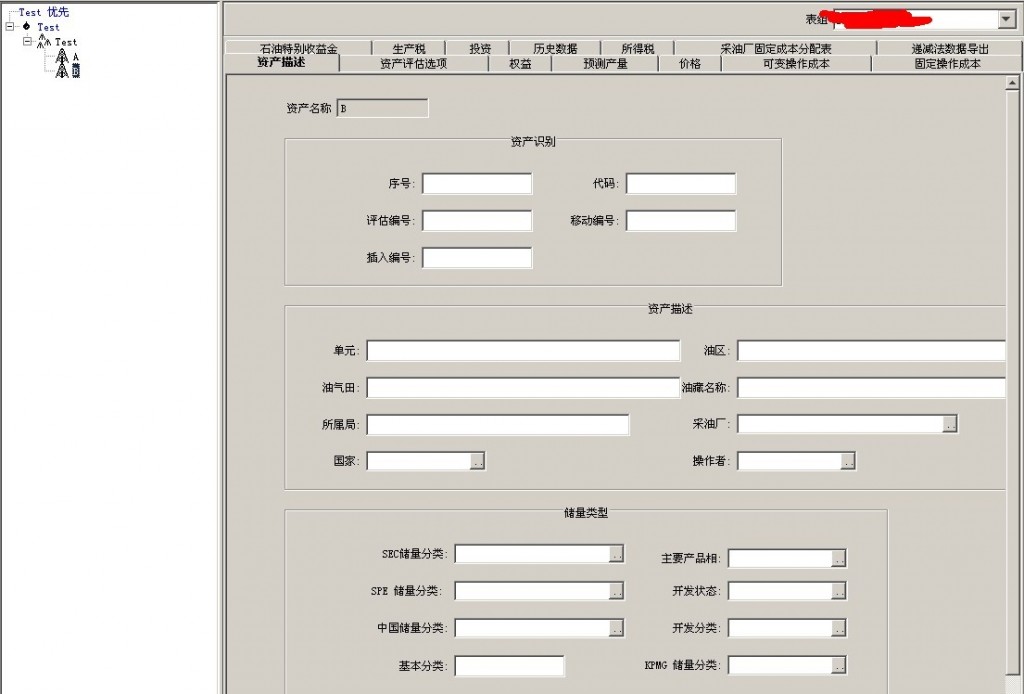
上述是一个树形结构,树上的数据大致是以 名称 类型 数据 这样的方式存储,类型有很多,不仅仅只是text,有各种类型包括大字段,日期等,不知道使用java的方式有没有什么好的思路,上述文件只是一个测试文件,内容较少,实际文件较大,10MB以上。 如何解析复杂的文本
[解决办法]
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.LinkedHashMap;
import java.util.Stack;
public class Parser {
public static final String DataFile = "Parser.data";
static class TreeData{
String name;
String type;
Object data;
}
static class TreeNode{
String name;
String title;
ArrayList<TreeNode> children = new ArrayList<TreeNode>(0);
LinkedHashMap<String, TreeData> datas = new LinkedHashMap<String, TreeData>();
}
static interface Converter{
Object convert(String data);
public static final Converter TextParser = new Converter() {
public Object convert(String data) {
return data;
}
};
}
/**
* 用例
*/
public static void main(String[] args) throws IOException {
BufferedReader reader = new BufferedReader(new InputStreamReader(Parser.class.getResourceAsStream(DataFile),"GBK"));
HashMap<String, Converter> converters = new HashMap<String, Converter>();
converters.put("text", Converter.TextParser);
TreeNode tree = null;
try{
tree = parse(reader,converters);
}finally{
reader.close();
}
printTreeNode(tree);
}
private static void printTreeNode(TreeNode node) {
System.out.println(node.name+" "+node.title);
if(!node.datas.isEmpty()){
for(TreeData data : node.datas.values()){
System.out.println("\t"+data.name+" "+data.type+" "+data.data);
}
}
if(!node.children.isEmpty()){
for(TreeNode tn : node.children){
printTreeNode(tn);
}
}
}
private static TreeNode parse(BufferedReader reader,HashMap<String, Converter> converters) throws IOException {
String line = null;
TreeNode root = new TreeNode();
Stack<TreeNode> stack = new Stack<TreeNode>();
stack.push(root);
while((line = reader.readLine())!=null){
line = line.trim();
int index = line.indexOf(')');
if(line.charAt(0)=='('){
if(line.charAt(1)=='"'){
TreeData treeData = parseTreeData(line.substring(1,index>0?index:line.length()),converters);
stack.peek().datas.put(treeData.name, treeData);
}else{
TreeNode treeNode = parseTreeNode(line.substring(1,index>0?index:line.length()));
stack.peek().children.add(treeNode);
stack.push(treeNode);
}
if(index>0 && index<line.length()){
for(int i=line.length()-index;i>(line.charAt(1)=='"'?1:0);i--){
stack.pop();
}
}
}else{
throw new IllegalStateException("数据格式异常,未以左括号开始");
}
}
return root.children.get(0);
}
private static TreeNode parseTreeNode(String line) {
String[] subData = line.split("\\s");
TreeNode treeNode = new TreeNode();
treeNode.name = subData[0];
treeNode.title = subData[1].substring(1,subData[1].length()-1);
return treeNode;
}
private static TreeData parseTreeData(String line, HashMap<String, Converter> dataParser) {
String[] subData = line.split("\\s");
TreeData treeData = new TreeData();
treeData.name = subData[0].substring(1,subData[0].length()-1);
treeData.type = subData[1].substring(1,subData[1].length()-1);
treeData.data = dataParser.get(treeData.type).convert(subData[2].substring(1,subData[2].length()-1));
return treeData;
}
}