hadoop ФҙВл·ЦОц(Ое)hadoop ИООсөч¶ИTaskScheduler
hadoop mapreduce Ц®ЛщУРДЬ№»КөПЦjobөДФЛРР,ТФј°Ҫ«job·ЦЕдөҪІ»Н¬datanode ЙПөДmapәНreduce task КЗУЙTaskSchduler НкіЙөД.
TaskScheduler mapreduceөДИООсөч¶ИЖчАа,өұjobClient МбҪ»Т»ёцjob ёшJobTracker өДКұәт.JobTracker ҪУКЬtaskTracker өДРДМш.РДМшРЕПўә¬УРҝХПРөДslotРЕПўөИ.JobTracker ФтНЁ№эөчУГTaskScheduler өДassignTasks()·Ҫ·ЁАаёшұЁёжРДМшРЕПўЦРә¬УРҝХПРөДslotsРЕПўөДtaskTracker ·ЦІјИООсЎў
TaskScheduler АаОӘhadoopөД өч¶ИЖчөДійПуАаЎЈД¬ИПјМіРЛьЧчОӘhadoopөч¶ИЖчөД·ҪКҪОӘFIFO,өұИ»ТІУРCapacity әНFairөИЖдЛыөч¶ИЖч,ТІҝЙТФЧФјәұаРҙ·ыәПМШ¶ЁіЎҫ°ЛщРиТӘөДөч¶ИЖч.НЁ№эјМіРTaskScheduler АајҙҝЙНкіЙёГ№ҰДЬЎў
ПВГжҫН FIFO өч¶ИЖчҪшРРјтөҘөДЛөГчЈә
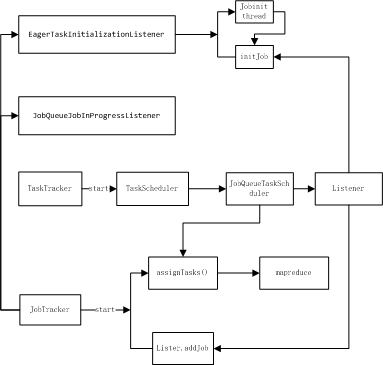
JobQueueTaskScheduler АаОӘFIFO өч¶ИЖчөДКөПЦАа.
1.КЧПИJobQueueTaskSchduler ЧўІбБҪёцјаМэЖчАаЈә
JobQueueJobInProgressListener jobQueueJobInProgressListener;
EagerTaskInitializationListener eagerTaskInitializationListener;
JobQueueJobInProgressListener О¬»ӨТ»ёцjobөДqueue ,ЖдЦРJobSchedulingInfo ЦР°ьә¬jobөч¶ИөДРЕПў:priority,startTime,id.ТФј° jobAdd update өИІЩЧчjobqueueөД·Ҫ·Ё
EagerTaskInitializationListener іхКј»ҜjobөДlistener ,ХвАпЛщОҪөДіхКј»ҜІ»КЗіхКј»ҜjobөДКфРФРЕПўЈ¬¶шКЗХл¶ФТСҫӯҙжФЪjobqueueЦР јҙҪ«ұ»ЦҙРРjobөДіхКј»Ҝ,
ЙПГж·Ҫ·ЁЦРХжХэЦҙРРtaskөД·Ҫ·ЁОӘЈә
obtainNewNodeOrRackLocalMapTask әНobtainNewNonLocalMapTask
ПВТ»ХЕПкПёөД·ЦОцХвБҪёц·Ҫ·Ё