NLP 学习笔记 04 (Machine Translation)
all is based on the open course nlp on coursera.org week 5,week 6 lecture
-------------------------------------------------------
时间匆匆啊,最近都比较忙,nlp这门课我在苦苦跟随,倒不是很难,就是平时有些忙,清明三天又因为一个比赛废了,有空了可能会写一篇推荐系统的东西,贴贴代码什么的~~下面还是做笔记吧
-------------------------------------------------------
①.Week5 机器翻译大家想必都用过吧,谷歌翻译百度翻译什么的,虽然绝大多数时候翻译得啼笑皆非,不过相对于以前的模型其精度已经高了很多了,第五周的课程主要介绍了Statistical Machine Translation的最早的两个模型,IBM Model 1 & IBM Model 2.相关资料:http://www.cs.columbia.edu/~mcollins/courses/nlp2011/notes/ibm12.pdf 1.Challenge 首先还是看看挑战吧,万变不离其宗,一切nlp的问题基本上都离不开语言的Ambiguity这个词,相同词汇在不同语句中的词性,意义都可能会不同。这还是在一门语言中,机器翻译涉及到两门语言,其问题更甚,比如同一个词可能会有很多种不同的翻译方法。 除此之外,不同语言的句子构成结构是不同的,比如下面是英语和日语的构句形式:
 2.Direct Machine Translation 最简单的翻译方法就是直接翻译,如你所想,一个词一个词地翻译,基本上是不懂英语的人的水平,翻译出来的结果可想而知。 不过这也是机器翻译的鼻祖了吧 对于一个词的翻译你得用很多歌if else来写,这样一个模型的缺点当然就很多啦,要靠人工来写if else,这是相当费时费力还不讨好的事情,而且没有考虑单词的意义。 除此之外还有一些“经典”的翻译模型,也就是过时的,落后的,比如通过分析两种语言不同的构句结构来调整语法树,从而得到翻译的句子。从结果来讲都没有statistic的模型来得有效 3.The Noisy Channel Model The Noisy Channel Model有两个部分组成:
2.Direct Machine Translation 最简单的翻译方法就是直接翻译,如你所想,一个词一个词地翻译,基本上是不懂英语的人的水平,翻译出来的结果可想而知。 不过这也是机器翻译的鼻祖了吧 对于一个词的翻译你得用很多歌if else来写,这样一个模型的缺点当然就很多啦,要靠人工来写if else,这是相当费时费力还不讨好的事情,而且没有考虑单词的意义。 除此之外还有一些“经典”的翻译模型,也就是过时的,落后的,比如通过分析两种语言不同的构句结构来调整语法树,从而得到翻译的句子。从结果来讲都没有statistic的模型来得有效 3.The Noisy Channel Model The Noisy Channel Model有两个部分组成:  我们用e代表英语,f代表法语,因为IBM的模型是在这两门语言上进行实验的。这里是由法语翻译为英语 通过很简单的概率论的转换我们就可以得到:
我们用e代表英语,f代表法语,因为IBM的模型是在这两门语言上进行实验的。这里是由法语翻译为英语 通过很简单的概率论的转换我们就可以得到:  我们的翻译结果就是argmax所得到的e。 注意:语言模型p(e)和我们之前定义的是一样的。而翻译模型我们会从很多句一一对应的英法语句中训练学习到。 这个模型是IBM两个模型的基础。 4.IBM 1 Model IBM 1模型引入了一个很重要的东西:Alignments,也就是词汇之间是如何关联的。很明显不同语言中同一个意思的句子词汇之间肯定会联系起来,这是翻译的基础。 比如说有如下两个句子:
我们的翻译结果就是argmax所得到的e。 注意:语言模型p(e)和我们之前定义的是一样的。而翻译模型我们会从很多句一一对应的英法语句中训练学习到。 这个模型是IBM两个模型的基础。 4.IBM 1 Model IBM 1模型引入了一个很重要的东西:Alignments,也就是词汇之间是如何关联的。很明显不同语言中同一个意思的句子词汇之间肯定会联系起来,这是翻译的基础。 比如说有如下两个句子: 
 l=6表示英语句子的长度 m=7表示法语句子的长度 一个alignment就是一个长度为m的序列,将f中的每一个词映射到e中,为了完善,我们会为e额外增加一个序号0,用来表示映射为空 比如说一个allignment:
l=6表示英语句子的长度 m=7表示法语句子的长度 一个alignment就是一个长度为m的序列,将f中的每一个词映射到e中,为了完善,我们会为e额外增加一个序号0,用来表示映射为空 比如说一个allignment:  就表示如下映射:
就表示如下映射: 
多个词可以映射到同一个词。 有了Alignments之后,我们就可以改变我的模型了,我们有如下定义
 这是总模型
这是总模型  其中a表示一个alignment 在这个过程中我们其实还可以得到很多有用的东西,比如说“最大可能的Alignment”,给你两个句子,必然有一个最大可能的映射 给定一个f,e,当然也就知道了l和m。我们有:
其中a表示一个alignment 在这个过程中我们其实还可以得到很多有用的东西,比如说“最大可能的Alignment”,给你两个句子,必然有一个最大可能的映射 给定一个f,e,当然也就知道了l和m。我们有:  值得一提的是,IBM Model 1虽然现在没有用于翻译,但它仍被用来寻找“最大可能的Alignment”
值得一提的是,IBM Model 1虽然现在没有用于翻译,但它仍被用来寻找“最大可能的Alignment”在Model 中:
 所有alignment都是一样的,这是一个很强的假设,但同时也是所有事情的开始~~~ 这是我们总的模型的右边部分,左边部分是上式:
所有alignment都是一样的,这是一个很强的假设,但同时也是所有事情的开始~~~ 这是我们总的模型的右边部分,左边部分是上式:  t是什么东西能,其实就是每个法语词汇对应所alignment的英语词汇的概率,举个例子:
t是什么东西能,其实就是每个法语词汇对应所alignment的英语词汇的概率,举个例子:  综上,IBM 1 Model :
综上,IBM 1 Model :  至于t到底怎么求,这个我们在后面会讲到。 5.IBM Model 2 我们先介绍一下Model 2中引入的新的元素:
至于t到底怎么求,这个我们在后面会讲到。 5.IBM Model 2 我们先介绍一下Model 2中引入的新的元素:  ,l,m还是和model 1中的定义一样,该式表示第 j 个法语中的词和第 i 个英语中的词互相关联的概率(在给出l和m的情况下) 然后有:
,l,m还是和model 1中的定义一样,该式表示第 j 个法语中的词和第 i 个英语中的词互相关联的概率(在给出l和m的情况下) 然后有: 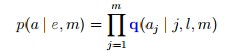
注意这就是Model 1中不同的地方了,Model 1中所有alignment的该项值都是相等的,这里是不等的 那么总的模型就是:
 这就是Model 2中和1的差别 6.EM Training of Models 1 and 2 那么怎么计算这两个模型呢,我们首先介绍alignment已经存在的情况,也就是训练集包括e,f,a 对t和q做如下统计计算:
这就是Model 2中和1的差别 6.EM Training of Models 1 and 2 那么怎么计算这两个模型呢,我们首先介绍alignment已经存在的情况,也就是训练集包括e,f,a 对t和q做如下统计计算:  具体的伪代码如下:
具体的伪代码如下:  这种情况相对比较简单,我们再来看训练集中没有a的情况:
这种情况相对比较简单,我们再来看训练集中没有a的情况:  其思想是EM算法的思想,通过下式计算
其思想是EM算法的思想,通过下式计算 ,来实现逐步地趋近于最优值,注意每次都会重新计算t和q的值
,来实现逐步地趋近于最优值,注意每次都会重新计算t和q的值  ②:Week 6
②:Week 6ps:这渣排版。。。。。写得我伤心
1.Introduction 第六周的主要内容是Phrase-based Translation Models(基于短语的翻译模型) 这个很好理解啦,我们平时看英文就知道翻译不能逐字地搞,有些短语是需要整体翻译的,这一周的课程讲的就是这样一个模型 比如下面这样一个例子:
这样我们将一个翻译拆分成了数个对应的短语的翻译,那么这样一个短语翻译(上面每个括号内的部分)的概率同样也可以用统计求得到:
当然这不是phrase模型的全部,我们对每一个翻译都有一个评分,我们用一个例子来说明:
这是翻译第一个短语的得分,等式右边的第一个部分叫做“语言模型”的得分,表示翻译后的语句是否是合法的英语,第二个部分叫“短语模型”,如你所见是单单这个短语翻译的得分,第三项叫做“失真模型”表示这个翻译的惩罚值,那个现在为0的地方是被翻译部分移动到现在位置的位移(直白点说就是原句被打乱的程度),如果原句的结构太乱了,会给以一定惩罚值。另一个例子:
为了方便,我们在这里重新定义一下所有的东西,一个“基于短语的翻译模型”包括三个东西:
1.短语模型,也就是上面的t,我们重新 给出一个符号g来描述:
2.一个三元语言模型.这和上面是一样的
3.一个失真模型,有一个distortion parameter:η(是负数)
对于每个短语p,有
这样一些东西,分别表示p开始的标号,结束的标号和对应翻译出来的英语短句
除此之外我们还有g(p)表示这个短语的得分
如果一些列的短语联合起来就可以翻译成一个句子,我们称之为一个derivation,一个derivation y有一些列的短语
比如对于这个句子:
可能会有一个y:
一个合法的derivation要满足以下几个条件:
1.每个词只能翻译一次,也就是所有的短语的s(p)和t(p)定义的区间是不能重叠的
2.跨度不能太大,要保证:
一大坨,什么东西呢,其实就是每个短语之间不能相差太远,d使我们设定的常数,比如为4
这样一步是为了在合理的范围内减小搜索的空间,比如上面那个y的例子,第一个和第二个短语之间的距离就是|3+1-7|=3,比选定的d=4小,所以是合法的
这样一个derivation我们同样给它一个得分:
h是以前提到的三元语言模型,由一坨q构成~~~~
2.Decoding Algorithm: Definitions一个状态的定义:(e1, e2, b, r,α ) e1和e2是两个英文单词,表示翻译的最后两个单词 b是一个长度为n的二进制序列,如果第i号位置为1,表示该单词已经被翻译了 r表示最后一个被翻译的单词的序号 α表示到目前为止该翻译的得分 eg:表示前三个单词已经被翻译且最后两个词为must 和also,,其得分为-2.5
相等函数的定义:如果q和q‘相等则返回true,相等的条件是:
next 函数的定义:next(q,p),其中q是一个状态,p是一个翻译的短语,nect函数返回q状态加入p项短语后的状态,,假设为q’,则有:
ph(q)函数的定义:返回一系列的翻译短语,并且对于状态q来说是合法的,也就是状态q加入这些短语后每个词只翻译了一次,以及它的失真在规定范围内:
Add(Q, q', q, p)函数的定义是:将状态q加入短语p后的状态q‘加入到集合Q中,集合Q是一系列的状态
具体的伪代码如下:一句话描述:有该状态存在则更新最优得分,无该状态存在则加入,用bp来记录反向指针
beam(Q)函数的定义:选择Q的的一个子集,Q是一个集合,包含一系列的状态 首先得到集合中最优的得分:(注:应该是max而不是argmax) 然后:
搞了半天,Q到底是什么呢?对于一个待翻译的句子,长度为n,我们设定Q0……Qn表示翻译了(0…n)个词的状态集合Decoding alogrithm的过程就是:
最后返回Qn中最高得分的状态,然后用bp指针一步步得到翻译出来的句子即可。




 这样一些东西,分别表示p开始的标号,结束的标号和对应翻译出来的英语短句
这样一些东西,分别表示p开始的标号,结束的标号和对应翻译出来的英语短句



 表示前三个单词已经被翻译且最后两个词为must 和also,,其得分为-2.5
表示前三个单词已经被翻译且最后两个词为must 和also,,其得分为-2.5 如果q和q‘相等则返回true,相等的条件是:
如果q和q‘相等则返回true,相等的条件是: 


 一句话描述:有该状态存在则更新最优得分,无该状态存在则加入,用bp来记录反向指针
一句话描述:有该状态存在则更新最优得分,无该状态存在则加入,用bp来记录反向指针 (注:应该是max而不是argmax) 然后:
(注:应该是max而不是argmax) 然后:  搞了半天,Q到底是什么呢?对于一个待翻译的句子,长度为n,我们设定Q0……Qn表示翻译了(0…n)个词的状态集合Decoding alogrithm的过程就是:
搞了半天,Q到底是什么呢?对于一个待翻译的句子,长度为n,我们设定Q0……Qn表示翻译了(0…n)个词的状态集合Decoding alogrithm的过程就是: 