java序列化3
上面的java,hessian和fastjson的序列化,说到底还是java内部之间的转换,也就是说序列化和反序列化都必须在java环境中,但是下面要说的apache thrift 和google protobuf和hadoop avro 则是不同语言之间的数据传递。
闲言少叙,具体看下:首先看下他们的哲学理念,也就是说他们为什么产生,是解决什么问题的。咱们公司的编程哲学是统一用java(部分算法以用c),这样可以做到最大程度的复用,但是在google和facebook ,他们的编程哲学是什么方便用什么,比如在后台用java方便,在前台用python方便,哪就后台用java,前台用python,又或者在某一个应用上用c比较好,那就用c,这样就会有一个问题,就是这些系统间的通信,也就是必须要解决这样一个场景,一个系统序列化的内容,其他系统必须能够反序列化出来,这就产生了google protobuf和apache thrift 顺便说一句,apache thrift 是facebook捐献出来的。他们为了解决这样的一个问题,定义了一个与语言无关的pojo描述文件,然后序列化的时候,根据描述文件,产生一个统一的文件,也就是这个最终的文件与语言无关,在反序列化的时候,根据这个描述文件和序列化文件,能够反序列化出来对应的pojo,hadoop avro和他们大致一样,但是一点小小的区别是avro 针对多条同一类型的数据,又做了一些优化,简单说,protobuf和thrift用来解决单个pojo的通信,而avro是用来解决pojo的list的通信
--------------------------------三种方式的比较
Protocol Buffers 是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化。它很适合做数据存储或 RPC 数据交换格式。可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。目前提供了 C++、Java、Python 三种语言的 API。
Apache Thrift 是 Facebook 实现的一种高效的、支持多种编程语言的远程服务调用的框架。
Avro是一个数据序列化的系统,它可以提供:1 丰富的数据结构类型2 快速可压缩的二进制数据形式3 存储持久数据的文件容器 4 远程过程调用RPC
5 简单的动态语言结合功能,Avro和动态语言结合后,读写数据文件和使用RPC协议都不需要生成代码,而代码生成作为一种可选的优化只值得在静态类型语言中实现
可以看到,Buffers和avro是一种序列化系统,而thrift是一个rpc框架,这个thrift中的序列化思路和Buffers差不多
?
首先来看下 Protocol Buffers,部署下载安装? http://code.google.com/p/protobuf/
从HelloWorld开始,在Protobuf??????????????????????????????????
package lm;
?message helloworld
?{
????required int32???? id = 1;? // ID
????required string??? str = 2;? // str
????optional int32???? opt = 3;? //optional field
?}
?
在上例中,package 名字叫做 lm,定义了一个消息 helloworld,该消息有三个成员,类型为 int32 的 id,另一个为类型为 string 的成员 str。opt 是一个可选的成员,即消息中可以不包含该成员。
Required,optional是message定义的关键字,详细的可以参看https://developers.google.com/protocol-buffers/docs/javatutorial?hl=zh-CN
用我们之前下载的protoc.exe来生成相应的代
protoc -I=. --java_out=. HelloWorld.proto
执行完成后,就会在当前目录下生成一个包含HelloWorld.java的lm文件夹,可以看到文件很大,达到了18k
?
?
?
测试代码如下:
helloworld.Builder hello = helloworld.newBuilder();
hello.setId(1);?? hello.setStr("2");?? hello.setOpt(123);
hello.build();
FileOutputStream output = new FileOutputStream("d:\\124.txt");
hello.build().writeTo(output);
将文件用16进制打开如下
?
?
0X8 0X1 0X12 0X1 0X32 0X18 0X7b
在分析这个代码之前,首先介绍几个概念,在http://www.iteye.com/topic/1113183 这篇文章中说,反序列化比较快的一个原因,对属性进行了排序,然后在反序列化的时候,有些token不再进行解析,在protobuf中,做的更加彻底,连toke都不写进去了,直接用数字替代,比如1,2,3等,代表第一个属性,第二个属性,这样文件大小就会更加小了。
采用这种 Key-value 结构无需使用分隔符来分割不同的 Field。对于可选的 Field,如果消息中不存在该 field,那么在最终的 Message Buffer 中就没有该 field,这些特性都有助于节约消息本身的大小。在本例中id为第一个属性,str为第二个,opt为第三个,
Key 用来标识具体的 field,在解包的时候,Protocol Buffer 根据 Key 就可以知道相应的 Value 应该对应于消息中的哪一个 field。Key 的定义如下:
(field_number << 3) | wire_type
?
可以看到 Key 由两部分组成。第一部分是 field_number,比如消息 lm.helloworld 中 field id 的 field_number为 1。第二部分为 wire_type。表示 Value 的传输类型。
Wire Type 可能的类型如下表所示:
Type
Meaning
Used For
0
Varint
int32, int64, uint32, uint64, sint32, sint64, bool, enum
1
64-bit
fixed64, sfixed64, double
2
Length-delimi
string, bytes, embedded messages, packed repeated fields
3
Start group
Groups (deprecated)
4
End group
Groups (deprecated)
5
32-bit
fixed32, sfixed32, float
因此 id对应的key是1000 为 16进制中的8,str对应的key是10010 16机制中的18 ,而opt对应的key是110000 16进制中的24,当然在写字符串的时候,会有字符串长度
因此0X8 0X1 0X12 0X1 0X32 0X18 0X7b的分析如下:
0X8 0X1? 后面的1是值,前面的8就是id的key
0X12 0X1 0X32? 前面的12是key代表18,然后1代表字符串长度,0X32就是ascii中的字符串2
0X18 0X7b 18为key? 7b就是123
2、 Varint :一种紧凑的表示数字的方法。它用一个或多个字节来表示一个数字,值越小的数字使用越少的字节数。这能减少用来表示数字的字节数。
比如对于 int32 类型的数字,一般需要 4 个 byte 来表示。但是采用 Varint,对于很小的 int32 类型的数字,则可以用 1 个 byte 来表示。当然凡事都有好的也有不好的一面,采用 Varint 表示法,大的数字则需要 5 个 byte 来表示。从统计的角度来说,一般不会所有的消息中的数字都是大数,因此大多数情况下,采用 Varint 后,可以用更少的字节数来表示数字信息。下面就详细介绍一下 Varint。
由于上面我们设置的都是比较简单的1,或者123 因此只要用1个字节就可以完成,不需要正常的int中的4个字节,减小了数据量
?
?你可能注意到Wire Type在 Type 0 所能表示的数据类型中有 int32 和 sint32 这两个非常类似的数据类型。Google Protocol Buffer 区别它们的主要意图也是为了减少 encoding 后的字节数。在计算机内,一个负数一般会被表示为一个很大的整数,因为计算机定义负数的符号位为数字的最高位。如果采用 Varint 表示一个负数,那么一定需要 5 个 byte。为此 Google Protocol Buffer 定义了 sint32 这种类型,采用 zigzag 编码。
使用 zigzag 编码,绝对值小的数字,无论正负都可以采用较少的 byte 来表示,充分利用了 Varint 这种技术。
其实上面的1和2就是protobuf中的Encoding在序列化的过程中,还要再讲一下:
首先是设置属性的时候的内容,在上面的测试中,有这么一部分hello.setId(1); ?具体的设置如下:
//这个值主要是用来判断id是否存在的,比如这个方法?? public boolean hasId() {return ((bitField0_ & 0x00000001) == 0x00000001);}
bitField0_ |= 0x00000001; ???
//将value设置到id_这个字段上
??????? id_ = value; ??????????????????
????????onChanged(); ?????????????????// 说明这个值已经改变了,通知用的
??????? return this;? ???????????????//方便用的,返回的还是builder。
真正的序列化过程很简单,在生成的代码中,可以找到这样的代码:
if (((bitField0_ & 0x00000001) == 0x00000001)) { output.writeInt32(1, id_);? }
????? if (((bitField0_ & 0x00000002) == 0x00000002)) { output.writeBytes(2, getStrBytes());? }
????? if (((bitField0_ & 0x00000004) == 0x00000004)) {output.writeInt32(3, opt_); }
由于所有的类型都已经定义好,不会出现不认识的pojo,因此序列化的时候是相当的快,那我们再来看下反序列化的内容,反序列化代码也很简单
??? helloworld hh = helloworld.parseFrom(new FileInputStream("d:\\124.txt"));
??? System.out.println(hh.getId());
???
而paseFrom里面的内容更加简单了
case 8: ??{ bitField0_ |= 0x00000001;?? id_ = input.readInt32();?????? break;? }
case 18: ?{ bitField0_ |= 0x00000002; ??str_ = input.readBytes(); ????break;? }
case 24: ?{ bitField0_ |= 0x00000004;?? opt_ = input.readInt32();???? break;? }
需要说明的是上面的这三段代码都是通过描述文件,生成的java代码,这样的代码进行反序列化怎么会不快
这边有一个Benchmarking,比较各个序列化的http://code.google.com/p/thrift-protobuf-compare/wiki/Benchmarking
最后说一句,据说淘宝就在用这种序列化方式。
下面我们简单看下 apache thrift? 站点http://thrift.apache.org/
和protobuf一样,这也是一个跨语言的序列化工具,但是这个更加强调的是rpc,rpc我们后面会讲到,此地我们只讲序列化
首先定义一个描述文件Hello.thrift ,其实后缀不一定是thrift,只要里面的内容满足要求即可
namespace java service.demo
?service Hello{
??string helloString(1:string para)
??i32 helloInt(1:i32 para)
??bool helloBoolean(1:bool para)
??void helloVoid()
??string helloNull()
?}
Thrift的定义类型见http://thrift.apache.org/docs/types/
thrift --gen java Hello.thrift
?
序列化大小参看http://blog.csdn.net/xqy1522/article/details/6942344的比较
仔细的观察代码你就会发现,这个要比protobuf序列化大的原因是类型判断没有做好,而是作为一个或者多个字节进行处理了。那普通的吸入int32来说
oprot.writeFieldBegin(NUM2_FIELD_DESC);
????? oprot.writeI32(this.num2);
??? ??oprot.writeFieldEnd();
首先是写入field的开始,然后写内容,最后是结束
writeFieldBegin中会写两个byte
writeByte(field.type);??? writeI16(field.id);
而 writeI32的内容也没有压缩
i32out[0] = (byte)(0xff & (i32 >> 24));
i32out[1] = (byte)(0xff & (i32 >> 16));
i32out[2] = (byte)(0xff & (i32 >> 8));
i32out[3] = (byte)(0xff & (i32));
trans_.write(i32out, 0, 4);
仍然是四个字节,因此在序列化的时候就不详细介绍这个东东了,在rpc的时候,详细讲
?
---------------------hadoop avro--------------------------------
下面看下hadoop avro
Avro(读音类似于[?vr?])是Hadoop的一个子项目,由Hadoop的创始人Doug Cutting(也是Lucene,Nutch等项目的创始人)牵头开发。Avro是一个数据序列化系统,设计用于支持大批量数据交换的应用。它的主要特点有:支持二进制序列化方式,可以便捷,快速地处理大量数据;动态语言友好,Avro提供的机制使动态语言可以方便地处理 Avro数据。站点地址http://avro.apache.org/
这个工具一个比较好的点是将描述文件,也就是scheme写入到了序列化文件中,这样就达到了一个自省或者自举的功能,下载的内容就不说了。举例说明
首先是一个简单的scheme,具体参看http://avro.apache.org/docs/current/spec.html
{
? "type" : "record",
? "name" : "Pair",
? "doc" : "A pair of strings",
? "fields" : [{
???????????? "name" : "left",
???????????? "type" : "string"
???????? }, {
???????????? "name" : "right",
???????????? "type" : "string"
???????? }]
}
很简单的一个定义类型为记录形式,名字为Pair? doc标示一个描述,属性有两个,1个name是left,类型为string,另一个name为right,类型为string
这个不需要生成文件了,下面看代码
Schema schema = Schema.parse(new File("Pair.json"));
?????? FileOutputStream out = new FileOutputStream("c:\\data.1");
?????? DatumWriter<GenericRecord> writer = new GenericDatumWriter<GenericRecord>(schema);
?????? Encoder encoder = EncoderFactory.get().binaryEncoder(out, null);
?????? GenericRecord datum = new GenericData.Record(schema);
?????? datum.put("left", new Utf8("L0"));
?????? datum.put("right", new Utf8("R0"));
?????? writer.write(datum, encoder);
?????? encoder.flush();
?????? out.close();
得到结果如下:
?
其中04为L0的Byte 长度,4c 和30为 L和0 而下面的04为R0的byte长度,52和30,则是R0,从这里可以看出,相对于protobuf,这个连1,2,3这样的排序都没有了,直接写的是值。
将right的属性改为int,同时设置为18,可以得到这样的文件
?
也是没有属性的顺序和类型的。在这里有一点数据库表的意思,scheme就是表的定义。
再看一种具有自举类型的序列化方式
Schema schema = Schema.parse(new File("Pair.json"));
????DatumWriter<GenericRecord> writer = new GenericDatumWriter<GenericRecord>( schema);?
?????DataFileWriter<GenericRecord> fileWriter = new DataFileWriter<GenericRecord>(writer);?
?????fileWriter.create(schema, new File("c:\\data.2"));?
?????for(int i=0;i<100;i++){
??? ????? ?GenericRecord datum = new GenericData.Record(schema);?
?????????datum.put("left", new Utf8("L"+i));?
?????????datum.put("right", new Utf8("R"+i));
?????????fileWriter.append(datum);
???? }
???? fileWriter.close();?
在这里,我们使用户了DataFileWriter,同时放入了50条数据,
?
?
?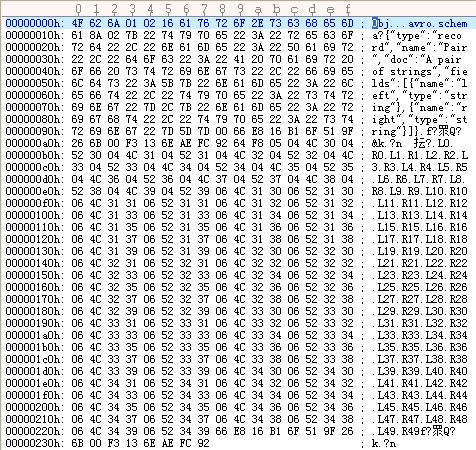
可以看到这里面将schema写入到了文件中,这样在进行反序列化的时候即使没有没有这个schema文件,也能够成功的序列化出来。
下面做一个简单的分析:
4f 62 6a 是作为一个magic存在的,而1标示版本号,这四个值是固定的
下面的2标示2个field
16 61 76 72 6f 2e 73 63 68 65 6d 61 22是字符串长度的一个计算公式(n << 1) ^ (n >> 31),后面标示avro.schema
后面的内容自己看下,基本上和之前的内容一致,遇到int型的直接写,遇到字符串型的,要先写字符串长度。
?
?
?