问一个算法,solution , 一直没想出来怎么做。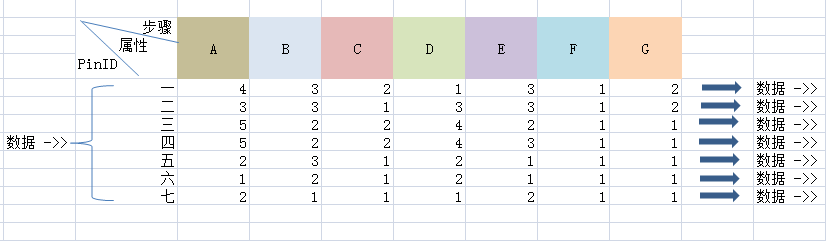
数据从左端输入,然后同时经过7个数据处理流程,每个流程都有一个数据出口。
每个数据处理流程都有7个处理步骤,每个步骤有不同的属性,不同的属性会导致该处理步骤的输出数据不一致。
最简单的方法是数据到来,即copy 7份数据给所有流程,然后各自流程的线程进行处理。但是这样的做法有浪费,性能不够好(空间性能),因为如上图,流程三和流程四有4个相同步骤,只需要流程三处理一次,流程四等待,然后在步骤D完成之后copy给流程四即可。
上表的处理流程应该如下:
另外,这张表中各步骤的属性可能是动态变化的,要求达到最优性能。
该怎么做呢?Thx 算法 多线程 性能优化
[解决办法]
也就是说完全有可能没有办法共享数据咯?比如第一个步骤的属性全部一样。
[解决办法]
全部不一样。
[解决办法]
我理解的意思就是对每个流程,找一个跟它有最长前缀匹配的流程。。不知是不是这样??如果是这样你把每个流程看作一个字符串,排一下序,然后跟它前边那个比较一下就得了。。
[解决办法]
这题思路挺有意思, 思路如下:
根据每个步骤构造一颗广义前缀树(trie树), 每个节点包含属性和执行的函数. 叶节点就是每个Task的最后一步.
主线程从根节点开始. 遇到N个分叉就构造N-1个线程并发运行(包括他自身就是N个线程), 每个线程运行次分叉处的N个子树的下一步(下一个节点). 这样对于每个线程, 就有了一个属于它的子树, 线程运行完一步(节点)后重复上述, 方式. 没有分叉, 继续运行下一步(节点), 有M个分叉, 构造M-1个线程, 并发运行下去.
[解决办法]
4楼果然是高人!
[解决办法]
都跟前一个匹配。。第二个跟第一个匹配,第三个跟第二个匹配。。