《有限分布算法》来了! 抛弃一致性哈希吧
声明
《有限分布算法》由本文作者原创,知识产权为本文作者所有。该算法可以用于个人研究,以及其他非商业性或非盈利性用途,但同时您应该遵守著作权法以及其他相关法律的规定,不得侵犯本文作者的合法权益。
?
算法简介
该算法使用时首先需要限定集群中节点的最大数量MAX,接下来我用一个简单的例子来描述这个算法的原理。假设集群中最多有10个节点,集群中现在有一个文件test.log,那么test.log就在集群中按如下规则分布:
?
?《有限分布算法》相对于“一致性哈希”而言,它显然可以在数据的均衡分布上表现的更好。由于所有数据都基于不同的随机数种子随机分布在集群中,因此它可以在理论上实现系统负载的完全均衡,而集群状态发生改变时,它也仅需要处理受到影响的那一部分数据副本。
?
《有限分布算法》的性能表现也优于“一致性哈希”,其中原理不再赘述,下文中的测试数据可以证明有限分布算法的性能优势。
?
测试数据
参与测试的“一致性哈希”实现代码如下所示:
测试数据分别为:数据分布图、节点宕机后数据流动量、计算分布时间。测试条件为:1000000个随机文件、20个节点(每个物理节点映射为分散的20个虚拟节点)。
?
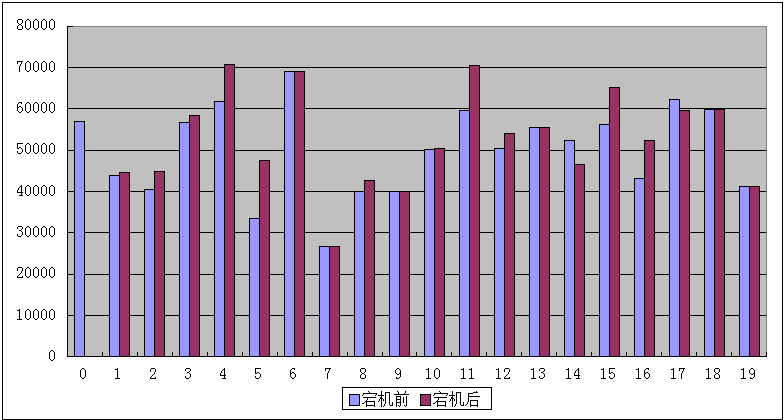
《一致性哈希》数据分布图(10.10.1.0宕机前、10.10.1.0宕机后)
?
算法执行时间:631-639毫秒
?
10.10.1.0宕机后数据移动量:55324(=该节点原分布数据量)
?
---------------------------------------分割线---------------------------------
参与测试的“有限分布算法”实现如下:
测试数据分别为:数据分布图、节点宕机后数据流动量、计算分布时间。?
测试条件为:1000000个随机文件、20个节点(每个物理节点映射为分散的20个虚拟节点)。
?
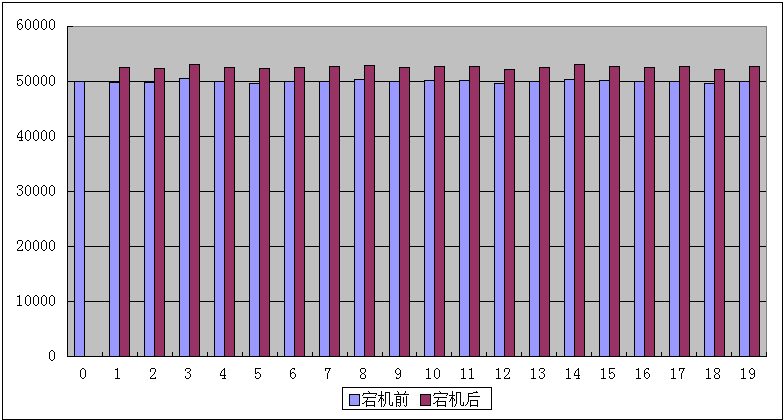
《有限分布算法》数据分布图(10.10.1.0宕机前、10.10.1.0宕机后)
?
算法执行时间:401-405毫秒
?
10.10.1.0宕机后数据移动量:49917(=该节点原分布数据量)
?
总结
根据测试数据我们可以很清晰的看到,一致性哈希的数据分布是非常不规则的,而有限分布算法的数据分布极其平均的。同时“一致性哈希”的计算性能与《有限分布算法》相比,降低了几乎50%,当然这也可能是笔者的算法实现不够完善所导致的。笔者会将全部源码以附件形式给出,如果你感兴趣的话可以下载源码自己尝试一下。
?
如果我们把《一致性哈希》所使用的“虚拟节点数量”增到至200、2000,这种分布的不规则性会在一定程度的得到抑制,但它永远也无法达到《有限分布算法》这样近乎完全平均分布的状态,并且“虚拟节点数量”的增加会进一步拉开《有限分布算法》与它之间的性能差距。总而言之一致性哈希的不规则分布是由该算法本身缺陷所导致的,即便技术非常精湛的工程师也无法弥补这个缺陷。如果你正在使用一致性哈希,现在你是否考虑抛弃它呢?
?
本文的讲解比较粗糙,这是因为《有限分布算法》只是笔者研究“分布式文件系统”时的副产品,具体详情会在下一篇博文中介绍。需要提前告知的是,笔者下一篇博文的挑战目标是现在名声大噪的HDFS,敬请期待。
?
作者:苏林
邮箱:sulinixl@gmail.com
?
转载请注明出处:http://sulin.iteye.com/blog/1915431