100 SQL2005跪求9亿数据存储方案~~~
数据库SQL2005
我有一个数据表 4个字段 4个字段都是浮点型 大概9亿记录 纯查询 不添加 查询的时候需要两个字段联合查询 两个字段联合才能唯一 是联合主键 查询的这个两个字段有规律是递增的
问题:
1. 9亿纯查询放一个表会不会性能很差?
2. 9亿数据查询 服务器需要多大的内存才能迅速?
3. 是按 两个字段递增规律存放在不同表好还是全部一起分区好?
4. 怎么分区?
各位大大跪求中.....
[解决办法]
第一个问题:分区是必须的,我想知道你的数据是什么?比如你可以按月来分区,按地区来分区,如果不知道你存放什么,很难分区,这部分请给出数据内容。9亿放一个表,有索引也快不了哪里去。
第二个问题:我记得当初我做BI的时候,2亿数据单表,不过列比你的多,需要40G空间,估计你的那个差不多,预计大概也要60G以上。
第三个问题:没必要这样分,直接放在分区就好了。分区自动会做处理。
第四个问题:这个和第一个问题合在一起,先要知道你的数据成分,然后才能确定分区方案,另外,联机丛书肯定有例子的。
补充一下,其实很少应用会存放9亿【活动】数据,很多都是【历史】、【静态】数据,对于这部分,在硬件层面,要把分区放到单独的数据文件中,然后把文件放到读性能高的磁盘上。缓解I/O压力。
另外,索引要考虑好,不过由于是2005,有些特性用不上,重点还是要看你的数据组成。
[解决办法]
不考虑硬件,查询的快慢,完全取决于LZ所设立索引与查询所需数据的匹配程度。
如果是大批量查询,比如其中的1亿行要一次查出,那么建立a,b上建立聚集索引要好些。
如果数据的离散性很大,比如也就几百行查出,建立非聚集索引要好些。
是否分区,要看lz在a,b两列上是否可以做出合理的业务相关分区,比如时间。
考虑到硬件的话,lz可将数据分到多个驱动器上,可以提高查询数据的提出效率。
[解决办法]
针对这样的查询:selcet c,d where a = ? and b = ?,只需要在(c,d)列上建个聚集索引即可(非聚集也行,但占用空间更大)。
其实楼主的问题挺简单的,各位把事情搞复杂了。
4个字段都是float,9亿行的表至多占用30多个G的空间。整个表占用的空间远比内存大,这就导致查询会使用物理读。可能这一点让各位想多了,但仔细想一下就知道,(c,d)列是唯一的,也就是selcet c,d where a = ? and b = ?最多返回一行数据,物理读撑死不过2、3次,根本没关系。
PS:那些动辄说分区的,其实SQL SERVER的分区功能远比你想像的弱,在楼主这种情况下,分区不能解决任何问题。(不同意我看法的,请列出你具体怎么分区,具体效果是什么)
PS2:另外,楼主,可以将这个表单独放到一个只读文件组里
[解决办法]
悲剧 重新认识分区 一切以事实说话,我承认我对分区认识不够
--------------------------------------这里尽可能模拟楼主的情况-----------------------------------
--------------------------------------一切以说明问题为主,不钻牛角尖-----------------------------------------
-----------------------------------一切以数据来说明问题-----------------------------------------
--创建分区函数,300W一个分区,计划插入1500W数据做测试
create partition function MyPartitonFun1(int)
as range right for values(3000000,6000000,9000000,12000000,15000000);
--创建分区方案
create partition scheme MyPartitonScheme1
as partition MyPartitonFun1
all to ([primary])
--建表,分区表
create table TestWithPartition (
ID1 int identity(1,1),
ID2 decimal(18,5),
Col3 decimal(18,5),
Col4 decimal(18,5)
)on MyPartitonScheme1(ID1)
--建表,没有分区的表
create table TestWithNoPartition (
ID1 int identity(1,1),
ID2 decimal(18,5),
Col3 decimal(18,5),
Col4 decimal(18,5)
)
--写入数据,温馨提示,
--这里的ID1的意图是为了模拟楼主所说的“有规律增长”,模拟楼主的情况,并不是特意搞的自增列
--下班开始搞,插入到700W多的时候sqlserver报错,神马.net freamwork异常,之后重启sqlserver继续写
--总数据是1400W多,将近1500W
declare @i int
set @i=0
while @i<15000000
begin
insert into TestWithPartition(Col3,Col4) values (rand()*10000000000,rand()*10000000000)
insert into TestWithNoPartition(Col3,Col4) values (rand()*10000000000,rand()*10000000000)
set @i=@i+1
end
--更新ID2,模拟楼主的情况
update TestWithPartition set ID2=ID1+rand() where ID2 is null
update TestWithNoPartition set ID2=ID1+rand() where ID2 is null
--创建聚集索引
create clustered index index_1 on TestWithPartition (ID1)
create clustered index index_1 on TestWithNoPartition (ID1)
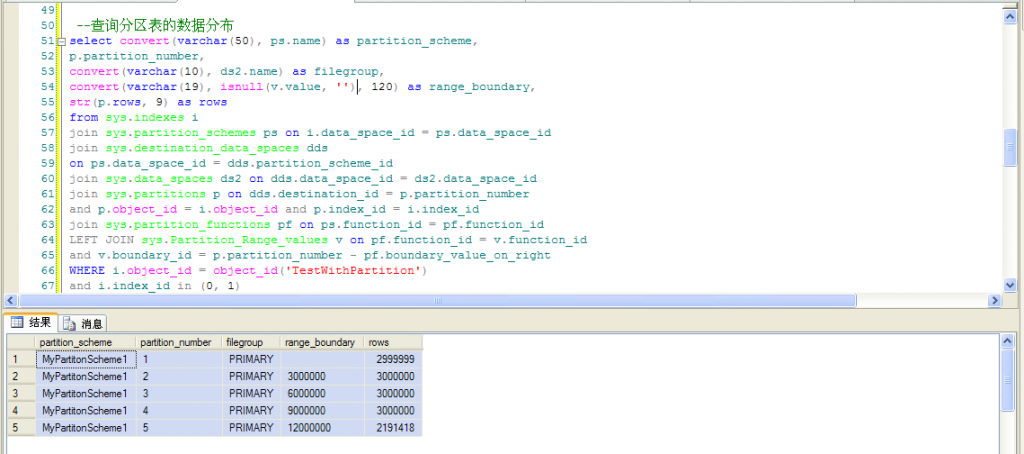
--查询分区表的数据分布
select convert(varchar(50), ps.name) as partition_scheme,
p.partition_number,
convert(varchar(10), ds2.name) as filegroup,
convert(varchar(19), isnull(v.value, ''), 120) as range_boundary,
str(p.rows, 9) as rows
from sys.indexes i
join sys.partition_schemes ps on i.data_space_id = ps.data_space_id
join sys.destination_data_spaces dds
on ps.data_space_id = dds.partition_scheme_id
join sys.data_spaces ds2 on dds.data_space_id = ds2.data_space_id
join sys.partitions p on dds.destination_id = p.partition_number
and p.object_id = i.object_id and p.index_id = i.index_id
join sys.partition_functions pf on ps.function_id = pf.function_id
LEFT JOIN sys.Partition_Range_values v on pf.function_id = v.function_id
and v.boundary_id = p.partition_number - pf.boundary_value_on_right
WHERE i.object_id = object_id('TestWithPartition')
and i.index_id in (0, 1)
order by p.partition_number
partition_schemepartition_numberfilegrouprange_boundaryrows
MyPartitonScheme11PRIMARY2999999
MyPartitonScheme12PRIMARY30000003000000
MyPartitonScheme13PRIMARY60000003000000
MyPartitonScheme14PRIMARY90000003000000
MyPartitonScheme15PRIMARY120000002191418
--开启I0,执行计划
set statistics io on
set statistics profile on
--清理缓存
dbcc dropcleanbuffers
select * from TestWithPartition where ID1='123456'
---从IO来看,确实差别不大啊,300W一个分区
(1 行受影响)
表 'TestWithPartition'。扫描计数 1,逻辑读取 3 次,物理读取 2 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
select * from TestWithNoPartition where ID1='123456'
(1 行受影响)
表 'TestWithNoPartition'。扫描计数 1,逻辑读取 3 次,物理读取 2 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
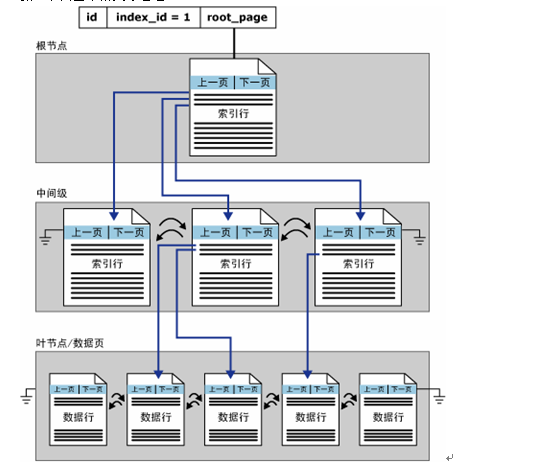
---------------------------------------------------这不由得使我想到了sqlserver的B树索引结构------------------------
图自己看,自己悟