Study-Hard-数据库连接及实现内部原理(下)
注:本文成文思路,来自炼数成金——《数据库引擎开发课程》——王涛老师
注:本文章,禁止未经允许的转载,但用于学习、研究目的的用处除外(注明出处:以链接的方式)
在数据库中,我们经常会用到如下操作:聚集(Group By)、去重—istinct)、关联等操作。
这些操作的前提,或者说本质上,都离不开排序操作,下面分别看下这些操作,并对关联进行着重讲解,通过讲解可以理解一定的SQL优化原理。
 通过上图,可以看书,GroupBy,进行排序操作,然后在对相同的记录进行GroupBy操作,这里的重点就是排序了。
通过上图,可以看书,GroupBy,进行排序操作,然后在对相同的记录进行GroupBy操作,这里的重点就是排序了。二、唯一DISTINCT
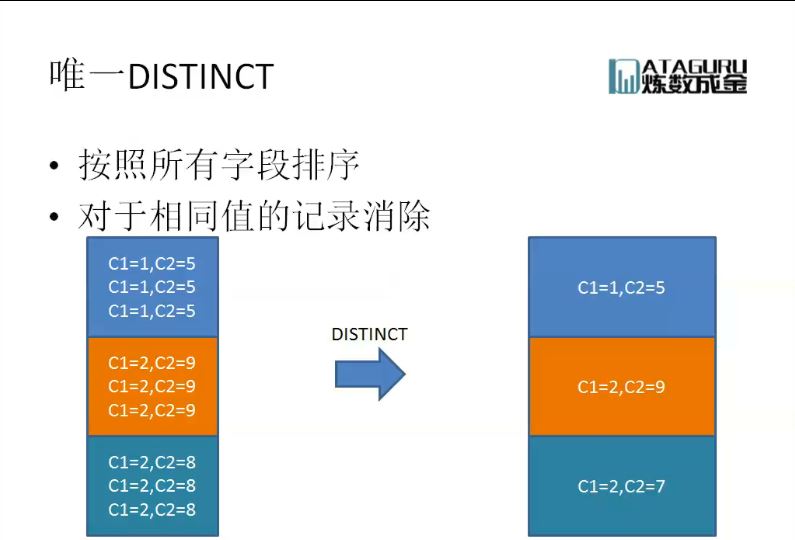 对于Distinct操作,首先仍是排序,排序后,则输出结果,这里需要一个比较操作,即用当前值与后续值进行比较,如果已经输出过,则不再输出。
对于Distinct操作,首先仍是排序,排序后,则输出结果,这里需要一个比较操作,即用当前值与后续值进行比较,如果已经输出过,则不再输出。三、关联操作 对于关联操作,也就是多表的关联,这里以量表为例,TableA、TableB;而相对来说,当表空间非常大,或者存在索引与否,对于sql的执行速度都是有影响的,通常而言,在关联操作时,会有三种:嵌套、归并关联、hash关联(在数据库连接及内部原理(上)有叙述),下面分别看看这三种关联,并附加实现代码。
3.1 嵌套循环
 对上图进行简单的解释,在进行嵌套循环的时候,通常情况是(大表+小表)的形式,并且会以小表作为内表,因为小表可以常驻内存,这样当进行磁盘IO的时候,只有大表会产生开销;反之,如果因为大表过大,则大表不能常驻内存,内外表的数据均存在与磁盘中,这样,进行磁盘IO开销是非常“可观”的:(。 解释了,谁做内外表的问题后,看下嵌套关联的操作过程: 1.取得要操作的表空间 2.对表空间的记录进行排序 3.通过嵌套循环进行赛选(如果是双表,可能是两个for嵌套) 4.获得需求的记录
对上图进行简单的解释,在进行嵌套循环的时候,通常情况是(大表+小表)的形式,并且会以小表作为内表,因为小表可以常驻内存,这样当进行磁盘IO的时候,只有大表会产生开销;反之,如果因为大表过大,则大表不能常驻内存,内外表的数据均存在与磁盘中,这样,进行磁盘IO开销是非常“可观”的:(。 解释了,谁做内外表的问题后,看下嵌套关联的操作过程: 1.取得要操作的表空间 2.对表空间的记录进行排序 3.通过嵌套循环进行赛选(如果是双表,可能是两个for嵌套) 4.获得需求的记录3.2 归并关联
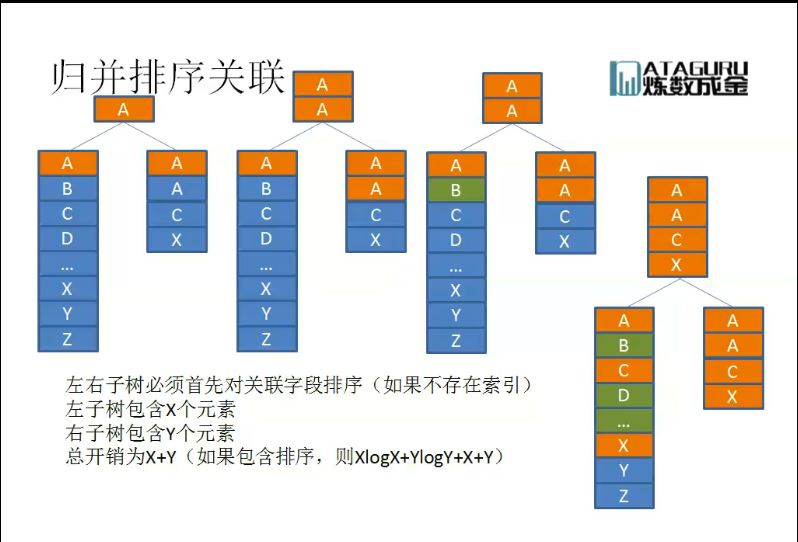
对与归并关联,有着很好的时间复杂度(如果两个表中的元素已经排序,如果未排序,时间开销可能为XlogX + YlogY + X + Y)。 那么,如何对排序好的元素进行关联呢: 1.首先每张表,会有一个指向头元素的指针 2.两个指针,进行比较,如果相同,则提出该元素 3.比较后续元素,谁小谁先向下移动 4.如此,一直到各自表的结尾
3.3 Hash关联(散列关联)
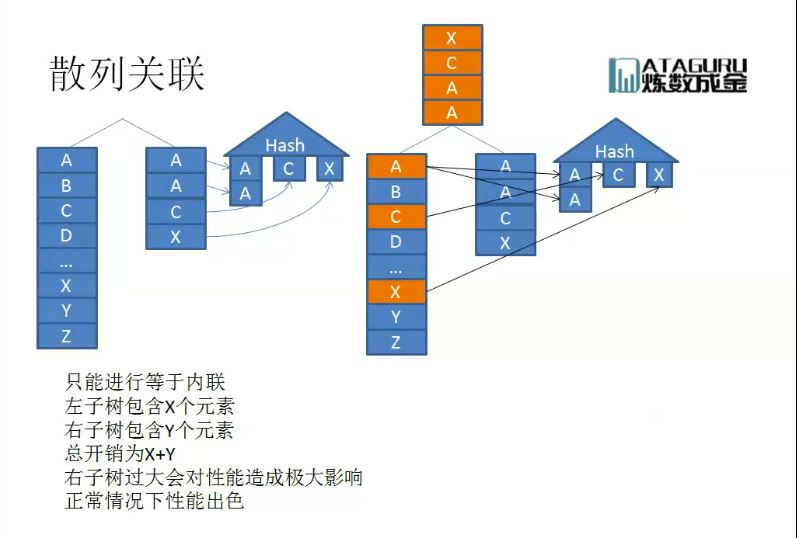
散列关联,则是对表进行散列后(不可超过内存的大小),另外一张表进行匹配;通常来说被散列的依旧是小表,匹配的过程需要匹配全部元素。 以上三种,根据以上三种关联方式,可以大致了解到一定的sql语句的原理以及调优机制,即为什么有的时候会加索引、或者不加、或者改变内外表的关联。
3.4 对三种关联进行简单的总结

三、三种关联的实现 试验环境:RedHat Linux 6.0 编 译 器:G++
3.1 给出归并排序的代码
#ifndef _MERGE_H__#define _MERGE_H__#include <stdio.h>#include <stdlib.h>void merge ( int _arr[], int head, int mid, int tail );void merge_sort ( int _arr[], int head, int tail );#endif
其他的三种代码上传至云盘:http://pan.baidu.com/s/1oqSZg