【Python】基于kNN算法的手写识别系统的实现与分类器测试
基于kNN算法的手写识别系统
1. 数据准备
使用windows画图工具,手写0-9共10个数字,每个数字写20遍,共200个BMP文件。
方法如下,使用画图工具,打开网格线,调整像素为32*32,如下图所示
将文件保存为单色BMP文件

1) 以二进制方式打开BMP文件3_0.txt
2) 根据BMP文件编码规则可知,单色位图BMP文件从第63-190位共128位是BMP位图数据部分。截取数据部分。

3) 将其转化为8位2进制文件,然后写入3_0.txt,并注意到每32个字节需要加入一个换行符
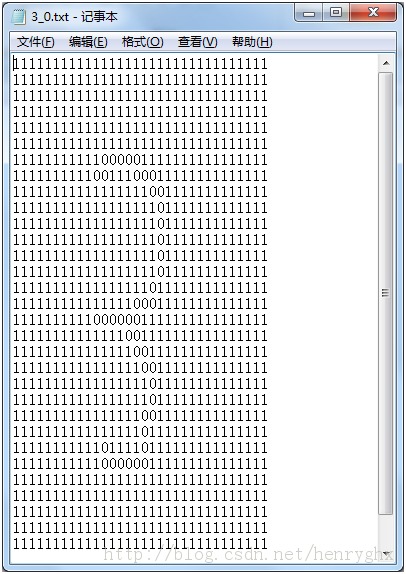
4) 调试中发现,上述文件是倒着的,因为BMP二进制数据存储顺序,从左到右,从下到上,重新将文件读入内存,然后按行倒序写入TXT文件
Python代码如下:

至此,批量实现BMP转换为同名TXT文件
3. kNN算法代码def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,1) + 1
sortedClassCount = sorted(classCount.iteritems(),key=operator.itemgetter(1), reverse=True)
returnsortedClassCount[0][0]
4. 欧氏距离算法代码dataSetSize= dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies= distances.argsort()
5. 马氏距离代码算法defclassify1(inX,dataSet,n,labels, k):
testFileList= listdir('testDigits') #iteratethrough the test set
mTest = len(testFileList)
distances=zeros((10,10))
for i in range(mTest):
diffMat = inX - dataSet[i]
diffMatT=(diffMat.T)
sqDiffMat = dot(diffMat,diffMat.T)
distances[n][i] = sqrt(sqDiffMat)
distanczzesArg=distances[n].argsort()
sortedDistIndicies=distanczzesArg
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,1) + 1
sortedClassCount = sorted(classCount.iteritems(),key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
6. 测试分类器,分析识别错误率
a) 欧氏距离
defhandwritingClassTest():
hwLabels = []
trainingFileList =listdir('trainingDigits') #loadthe training set
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i] #0_0.txt
fileStr = fileNameStr.split('.')[0] #take off .txt 0_0
classNumStr =int(fileStr.split('_')[0])#0
hwLabels.append(classNumStr)
trainingMat[i,:] =img2vector('trainingDigits/%s' % fileNameStr)
testFileList = listdir('testDigits') #iterate through the test set
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr =fileNameStr.split('.')[0] #take off.txt
classNumStr =int(fileStr.split('_')[0])
vectorUnderTest =img2vector('testDigits/%s' % fileNameStr)
classifierResult =classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print "the classifier came backwith: %d, the real answer is: %d" % (classifierResult, classNumStr)
if (classifierResult != classNumStr):errorCount += 1.0
print "\nthe total number of errorsis: %d" % errorCount
print "\nthe total error rate is:%f" % (errorCount/float(mTest))
基于kNN手写识别算法测试结果
the classifiercame back with: 0, the real answer is: 0
the classifiercame back with: 1, the real answer is: 1
the classifiercame back with: 0, the real answer is: 2
the classifiercame back with: 0, the real answer is: 3
the classifiercame back with: 4, the real answer is: 4
the classifiercame back with: 5, the real answer is: 5
the classifiercame back with: 0, the real answer is: 6
the classifiercame back with: 7, the real answer is: 7
the classifiercame back with: 8, the real answer is: 8
the classifiercame back with: 9, the real answer is: 9
the total numberof errors is: 3
the total errorrate is: 0.300000
1) 如何将BMP文件批量转换为32X32的TXT文件很关键,期间也遇到了如下问题,不断调试代码,最终成功生成
a) 提取BMP二进制数据,查阅BMP编码规则,对于黑白单色BMP文件从63字节起是BMP数据部分
b) 直接读取BMP文件,获取的是16进制字符串,需要循环使用ord()函数逐字节将16进制字符串转为起对应10进制数值,然后10进制转为2进制(注意许指定二进制位数为8位)
c) 写入TXT文件,默认没有换行,需要每4个16进制字节后插入一个”\n”,形成32行32列的2进制字符串
d) BMP二进制数据存储顺序,从左到右,从下到上存储。读取到32X32的TXT文件后,发现字符形状是倒置的,需要翻转TXT的行,将32行替换为第1行,第31行替换为第2行….
2) kNN算法,错误率比较高,当trainingDigits只有200个时,识别0-9数字,错误率可能达到30%
3) 手写笔迹如果太细,识别错误率较高
4) 准确理解欧式距离和马氏距离的含义是至关重要的,尤其是马氏距离,需要注意u代表是由同一类数字多次训练的算术平均值组成的(1,1024)数组