使用纯javascript通过className来获取元素 (getElementsByClassName Speed Comparison)
document.getElementsByClass = function(needle) { function acceptNode(node) { if (node.hasAttribute("class")) { var c = " " + node.className + " "; if (c.indexOf(" " + needle + " ") != -1) return NodeFilter.FILTER_ACCEPT; } return NodeFilter.FILTER_SKIP; } var treeWalker = document.createTreeWalker(document.documentElement, NodeFilter.SHOW_ELEMENT, acceptNode, true); var outArray = new Array(); if (treeWalker) { var node = treeWalker.nextNode(); while (node) { outArray.push(node); node = treeWalker.nextNode(); } } return outArray; }?The Ultimate getElementsByClassName
Uses a pure DOM implementation, tries to make some optimizations for Internet Explorer.
function getElementsByClassName(oElm, strTagName, strClassName){ var arrElements = (strTagName == "*" && oElm.all)? oElm.all : oElm.getElementsByTagName(strTagName); var arrReturnElements = new Array(); strClassName = strClassName.replace(/\-/g, "\\-"); var oRegExp = new RegExp("(^|\\s)" + strClassName + "(\\s|$)"); var oElement; for(var i=0; i<arrElements.length; i++){ oElement = arrElements[i]; if(oRegExp.test(oElement.className)){ arrReturnElements.push(oElement); } } return (arrReturnElements) }?最新更新请点击这里,或者看附件。
?Dustin Diaz’s getElementsByClassA pure DOM implementation, caches the regexp, and is generally quite simple and easy to use.
?
It's simple. It works just how you think getElementsByClass would work, except better.
- Supply a class name as a string.(optional) Supply a node. This can be obtained by getElementById, or simply by just throwing in "document" (it will be document if don't supply a node)). It's mainly useful if you know your parent and you don't want to loop through the entire D.O.M.(optional) Limit your results by adding a tagName. Very useful when you're toggling checkboxes and etcetera. You could just supply "input". Or, if you're like me, and you said Good Bye to IE5, you can use the "*" asterisk as a catch-all (meaning 'any element).
function getElementsByClass(searchClass,node,tag) { var classElements = new Array(); if ( node == null ) node = document; if ( tag == null ) tag = '*'; var els = node.getElementsByTagName(tag); var elsLen = els.length; var pattern = new RegExp("(^|\\s)"+searchClass+"(\\s|$)"); for (i = 0, j = 0; i < elsLen; i++) { if ( pattern.test(els[i].className) ) { classElements[j] = els[i]; j++; } } return classElements; }?Prototype 1.5.0 (XPath)Mixes an XPath and DOM implementation; using XPath wherever possible.
document.getElementsByClassName = function(className, parentElement) { if (Prototype.BrowserFeatures.XPath) { var q = ".//*[contains(concat(' ', @class, ' '), ' " + className + " ')]"; return document._getElementsByXPath(q, parentElement); } else { var children = ($(parentElement) || document.body).getElementsByTagName('*'); var elements = [], child; for (var i = 0, length = children.length; i < length; i++) { child = children[i]; if (Element.hasClassName(child, className)) elements.push(Element.extend(child)); } return elements; } };?Native, Firefox 3A native implementation, written in C++; is a part of the current CVS version of Firefox, will be included in Firefox 3.
document.getElementsByClassName?The Speed Results
For the speed tests I copied the Yahoo homepage into a single HTML file and used that as the test bed. They make good use of class names (both single and multiple) and is a considerably large file with lots of elements to consider.
?
You can find the test files, for each of the implementations, here:
http://ejohn.org/apps/classname/
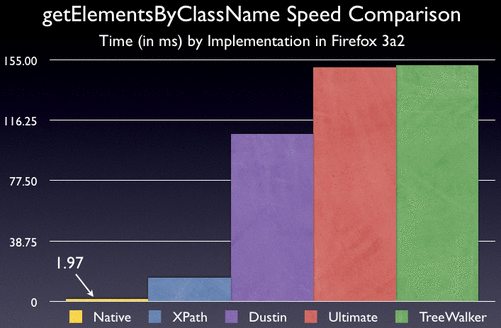
Note: “XPath” is just Prototype’s implementation.
?
From these figures we can see that the native implementation of getElementsByClassName, in Firefox 3, is a full 8x faster than the XPath implementation. Additionally, it’s a stunning 77x faster than the fastest DOM implementation.
Note: These numbers have been revised from what was originally posted as the lazy-loading nature of
document.getElementsByClassNamewasn’t taken into account. The resulting arrays are completely looped-through now, making sure that all elements are accounted for.
Currently, Prototype has the best general-use implementation: Use XPath selectors wherever possible, fall back to fast DOM parsing.
?
Interestingly, only Prototype actually tries to implement the document.getElementsByClassName interface (all others do one-off names). However, Prototype doesn’t check to see if the document.getElementsByClassName property already exists, and completely overwrites the, incredibly fast, native implementation that Firefox 3 provides (oops!).
?
In all, the results are quite astounding. The native implementation is absolutely much faster than anything I could’ve imagined. It completely decimates all the other pieces of code. I can’t wait until this hits the general public users will, absolutely, feel a significant increase in speed.
?
来源: http://ejohn.org/blog/getelementsbyclassname-speed-comparison/
参考:http://stackoverflow.com/questions/3808808/how-to-get-element-by-class-in-javascript
function replaceContentInContainer(matchClass,content) { var elems = document.getElementsByTagName('*'), i; for (i in elems) { if((' ' + elems[i].className + ' ').indexOf(' ' + matchClass + ' ') > -1) { elems[i].innerHTML = content; } }}?
我的实例:
<script type="text/javascript"> function getElementsByClass(searchClass,node,tag) { var classElements = new Array(); if ( node == null ) node = document; if ( tag == null ) tag = "*"; var els = node.getElementsByTagName(tag); var elsLen = els.length; var pattern = new RegExp("(^|\\s)"+searchClass+"(\\s|$)"); for (i = 0, j = 0; i < elsLen; i++) { if ( pattern.test(els[i].className) ) { classElements[j] = els[i]; j++; } } return classElements; }var gd = getElementsByClass("common_li",document.getElementById("show_thumb_photo"),"li");alert(gd[0].innerHTML);</script>?